4 OPTIMISATION OPTIONS (SLICE & PRISM)
Features for evaluation and reporting that are common to both Slice and Prism methods are covered in this section.
4.1 Model Discretisation
Model discretisation, by which we mean “subdividing the original block model into smaller sub-cells”, is required for two primary purposes:
(1) The stope-shape annealing algorithm, where the dimension of the stoping units and sub-units relative to the model cells must be considered, and changes in the wireframe shape must evaluate to a different volume to identify improvements in stope value
(2) Maintaining an accurate volumetric estimate of material mined out in stoping units and sub-units.
Model discretisation also has an influence on accuracy of grade and tonnage estimation, particularly for the case when model and/or framework are rotated and the rotations are different.
The Fast or (cell-centreline) evaluation method uses a “ray-trace” procedure (likened to a drill-hole trace) passing through each cell-centroid in the discretised block model, to evaluate the proportion of a cell in a wireframe shape. The distribution of the ray-traces plays a significant role in various SSO processes, output accuracy and processing effort.
Discretisation ensures the model cell sizes are small enough to achieve the required ray-trace density for annealing and evaluating the stope-shape, honouring pillar widths (especially for sub-stopes) and allowing for the flagging of “mined-out” material. A minimum of 2 ray-traces on both U and V axes (i.e. for strike and elevation) are required per stope or sub-stope shape to allow the annealing process to identify changes in the stope volume.
Discretisation is completed prior to the seed-slice, seed-shape and anneal processes. The size of the discretised cells is the driver for the number of ray-traces; not the original model cell sizes.
The default discretisation setting is 4x4. This setting generally satisfies simple sub-stope requirements (i.e. 2 vertically and 2 along strike to achieve a minimum of 2 ray-traces per sub-stope shape). If there are only full-stopes, this parameter could be reduced to 2x2.
The discretisation setting must also take into account the full-stope and sub-stope intervals as defined by irregular frameworks (i.e. such as irregular level spacing). The maximum discretisation number is 40x40.
The discretisation number and dimension of the framework on the U and V axes determines the maximum discretised cell size along U and V axes. Any cell with a greater size is subdivided into equal intervals so that the discretised cell dimension does not exceed the maximum. Note that this is not the same as superimposing a fixed grid of the maximum discretised cell size over the model cells.
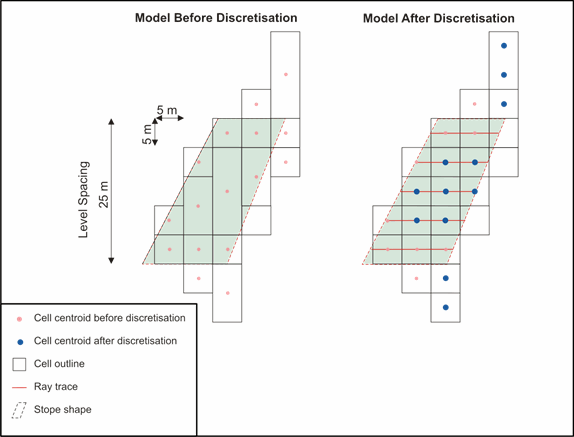
To illustrate the discretisation process, the following provides an example of the discretised Z value for a regular level framework using 25m level spacing relative to a model with parent-cells that could be up to 15m high (sub-cells down to 5m) and discretisation setting of 4 in the Z direction:
· The maximum discretised cell size in the Z direction is determined by the stope level spacing divided by the discretisation number e.g. a 25m level spacing divided by 4 is 6.25m.
· The 15m high cells exceed the maximum discretised Z interval of 6.25m as determined above. These cells are split by an integer divisor - up to the maximum discretisation number - to achieve a cell height that is equal to or less than 6.25m. In this case, it is 3, and results in a split cell height of 5m (15m / 3).
· Referring to the example illustrated in Figure 4‑1(noting that each red cell is equivalent to 5m x 5m with the central parent-cell being 15m high x 5m wide.
· The highlighted centroids represent what the cell split would look like after the discretisation process.
· In this example, horizontal ray-traces (in red) define the proportion of each discretised model cell that falls within the stope wireframe. For this example 5 ray-traces would cover the vertical extent for the full-stope shape (corresponding to each distinct cell centroid Z value).
Figure 4‑1 Block Model Discretisation Example
4.2 Cut-off and Head-grade
Cut-off and head-grade are defined as follows:
· Cut-off– is used as a stope-shape boundary descriptor by defining rock as either ore (equal to or above cut-off) or waste (below cut-off).
· Head-grade–is used as a stope volume descriptor. The head-grade can be supplied in addition to the cut-off. A user might not want to have “marginal grade or marginal value” stopes, and so setting the head-grade higher than cut-off, will return the more profitable stopes (e.g. it might relate to a desired profitability), or stopes that have a higher probability of meeting the cut-off grade.
The cut-off grade can be supplied without the head-grade, but a head-grade cannot be supplied without a cut-off grade.
The optimisation field can either be a grade field or a value field. If the optimisation field is a value field then the optimisation objective is to maximise the total value of the stope above the cut-off, and a stope value less than the cut-off would be sub-economic. It is the maximisation of the profitability of the stope relative to the cut-off. If the optimisation field is a grade field, then the equivalent objective is to maximise the total metal above the cut-off.
There is also an optional function that can be applied to the cut-off only or cut-off with head-grade to optimise total value or total metal while satisfying the cut-off or head-grade. This function maximises recovery of metal (i.e. kilograms) or total dollar value ($) and will attempt to recover all possible metal or dollar value while still meeting the overall cut-off or cut-off with head-grade criteria for the stope. However, it does not maximise the metal grade per tonne (i.e. g/t) or value per tonne (i.e. $/t). This option is likely to be desirable to users who value (i.e. rank) maximising metal recovery above maximising head-grade. It could be used to answer the question "how many grams can be mined at a profit" rather than "which grams to mine to maximise profit"
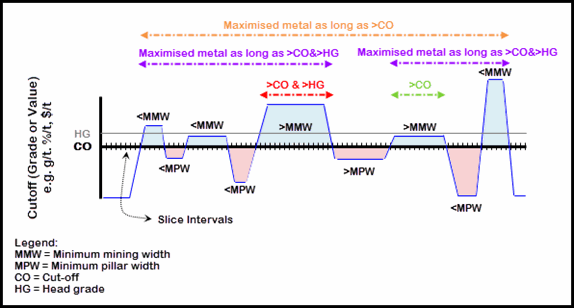
Figure 4‑2 illustrates at a high-level the general cut-off, head-grade and optimised total value / optimised total metal concepts. Intervals above (blue) and below (red) cut-off identified, and the length of the interval relative to the minimum stope width (<MMW,>MMW) and the minimum pillar width (MMPW,>MPW) are identified. The area contributions above the cut-off (blue) have a positive contribution and the areas below the cut-off (red) have a negative contribution, with the goal to have a net positive area outcome.
A head-grade is specified in addition to the cut-off grade. Four different outcomes are possible for this data set:
· Interval greater than cut-off grade
Includes both ">CO", and ">CO & >HG"
· Interval greater than cut-off and head-grade
Only ">CO & >HG"
· Interval greater than cut-off grade with optimise total value or total metal option
Includes both "Maximised metal as long as >CO" and "Maximised metal as long as >CO & >HG"
· Interval greater than cut-off grade and head-grade with optimise total value or total metal option
Only "Maximised metal as long as >CO & >HG"
The right-most (blue) interval is above cut-off but is less than the minimum stope width, and makes no net positive contribution when added to the interval to the left. It will only be included in a stope if the optimise total value or total metal option is selected.
Figure4‑2 Simplified Cut-off, Head-grade Maximised Metal-Value Concept
The cut-off and head-grade numbers can be supplied as:
· A fixed number (either as a grade per mass unit e.g. g/t, or currency value per mass unit e.g. $/t),
· Values from the block model so that the value has a spatial property e.g. to vary cut-off with depth (with a default value applied if the field value for a given cell is ‘absent’ or if cells are absent from the model),
· A relationship between the value and some other variable related to the stope dimension, specified as points on a curve e.g. the cut-off is a function of stope width so that narrow stopes have a higher cut-off and wider stopes have a lower cut-off This option allows the Optimiser to dynamically choose between bulk and selective mining by making the cut-off and head-grade a function of the stope size, and choosing the mining shapes that return maximum value.
Note that where a grade field is supplied, a Calculated Value can be computed taking into account commodity price, mining and processing costs, mining and process recoveries, and royalty. The calculated value uses the formula:

4.2.1 Cut-off Grade using Curve Table
Thick, Mass, Height and Area all relate to the stope size or dimension. Apart from mass, one would expect the other dimensions of the stope (other than the one selected) to be roughly constant. Mining cost can then be related to Hydraulic Radius (the ratio of area and perimeter) and hence the cut-off can be used as a proxy to quickly establish whether larger or smaller stopes are better in the optimisation.
e.g. If the primary dimension controlling the cost is the stope width, (which may vary according to orebody width, the number of lenses and included waste proportion), then this method of dynamically specifying the cut-off variable will allow the best stope width to be chosen on a local area basis, per level and section - as a function of cost.
A number of stope dimension variables are provided in the Version 2 implementation:
· thick (W dimension i.e. width for XZ|YZ, height for XY|YX),
· area (UW dimension),
· height (V dimension),
· mass,
· roof_hydraulic_radius (UW dimension), calculated as {area/perimeter},
· wall_hydraulic_radius (UV dimension), calculated as {area/perimeter}
· section_hydraulic_radius (VW dimension), calculated as {area/perimeter}.
The cut-off or head-grade value is interpolated between the curve points supplied, and otherwise uses the minimum or maximum curve point values if the dimension falls outside the values supplied. Note that the cut-off or head-grade value to be used as a discriminator is assigned in the seed generation stage, based on the seed-shape. Therefore the final stope dimension may not exactly match the defined relationship after annealing.
4.3 Evaluation Methods
The stope-shape annealing procedure incrementally improves the value of the stope-shape. This can require thousands of iterations, and the adjusted stope must be evaluated against the block model repeatedly. This is a relatively time consuming analysis to embed in an optimisation procedure.
Two methods of evaluation are available:
4.3.1 Exact Evaluation
This is the method used traditionally in mine planning software where an exact geometric (or Boolean) intersection of cells overlapping with the stope wireframe is made. This is termed “wireframe-cell-evaluation” (and has been labelled "Exact" or "Precise" in various contexts).
The method is actually the more conservative evaluation method as it evaluates only the proportion of the cell within the wireframe surface used. Accuracy depends on the sub-celling detail as the evaluation method cuts the “corners” off cells that lay outside of the wireframe surface (hence understates metal inventory) and can also include additional wedges of rock with no grade from the absent cell portions inside the wireframe surface, as depicted in Figure 4‑3
4.3.2 Approximate Evaluation
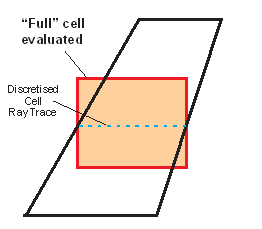
A faster method designed for (discretised) sub-cell block models has been implemented using ray-tracing techniques. This is termed “cell-centreline-evaluation” (and has been labelled "Approximate" or "Fast" in various contexts). Note that the results are not indicative of the name used (“Approximate”) but rather of the volume calculation technique applied.
The method uses a ray-trace through the sub-cell centroid (along the Model Discretisation Plane W-axis) to intersect the wireframe shape, and calculate the portion of the sub-cell (from the trace) that falls within the wireframe shape.
For CAE Studio block models, the cell-centreline method is used in the TRIFIL process to create sub-cell models within a wireframe. Using the same cell-centreline for evaluation of stope wireframes means that the sub-cell approximations are common between the original model creation procedure and the stope evaluation technique in SOO. Hence geometric errors are minimised. This is less the case if model cells are split in the discretisation process. Where smaller sub-cells are used at the wireframe boundary, the better the approximate method becomes at replicating the wireframe shape for the case of sharp grade boundaries.
4.4 Comparing Results from Exact and Approximate Evaluation
The results from the faster “approximate” method can be different from the results obtained by the “exact” method, and these differences are summarised for each stope output in the log file, reporting the percentage difference in tonnes, grade/value and metal/accumulation calculated between the two methods.
The volumes and tonnes for the “approximate” and “exact” methods are identical for a constant model density (with small differences for variable density), but the contained value or contained metal may be different. The differences can all be attributed to the sub-cell approximations used in block modelling of 3D surfaces and shapes (volumes).
Both methods of evaluation are made available, but the runtimes can increase by a factor of 5-10 for the “exact” method. The run-times for the "approximate" method will also be slower for the case when the rotation angles for the block model and stope-shape framework are different (due to the additional geometry calculations required). Note also that increasing the number of sub-cells will reduce the sampling error at boundaries, but this will be at the cost of significantly increasing the processing time taken.
4.4.1 Interaction of Evaluation Methods with Reporting
While two methods are available for evaluation and annealing, three methods are available for reporting.
i. Exact Evaluation - Exact Reporting
Uses the Exact method for wireframe evaluation, and the same results for reporting
ii. Approximate Evaluation - Approximate Reporting
Uses the Approximate method for wireframe evaluation, and the same results for reporting
iii. Approximate Evaluation - Exact Reporting
Uses the Approximate method for wireframe evaluation, but re-evaluates the final stope wireframes for reporting with the “Exact” method.
Note that for marginal stopes, the differences in exact and approximate evaluation may result in a stope becoming sub-economic because the exact evaluation can produce a more conservative result.
Care should be taken to ensure that the default value for the optimisation field is realistic for ore-only block models.
Figure 4‑3 Exact Evaluation Method after Discretisation
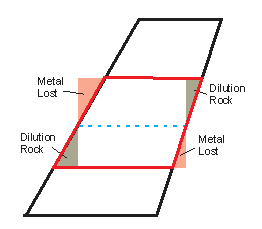
Figure 4‑4 Faster Approximate Evaluation Method after Discretisation
4.5 Reporting Options
Apart from the standard model definition fields, the mandatory model fields are the optimisation field(typically a metal grade or dollar value per tonne) and the density field. Regarding the optimisation field, this may be a grade field (which cannot be negative in the optimisation process) or a value field (which may have negative values in the optimisation process).
Other optional model reporting fields are allowed. All mandatory and any additional optional fields are output to the stope wireframe, string file and run report. Each field can have optional control on scaling applied (1,000’s, millions, imperial to metric 0.3048, etc.) and accumulation methods (mass average, dominant, ranked, etc.). For alpha fields, the categories of [dominant, ranked] are available.
Options provide reporting for:
-
Exclusion field to ignore the reporting of items such as voids, topography air, or backfill. Note, if you have backfill in the "stope void", do not associate this with the "report_exclusion_field". Backfill should have a density and grade, and should effectively be reported as waste. The VOID field type is the true void or cavity, as identified by the "report_exclusion_field".
-
Separate reporting of the undiluted and diluted stope-shapes (total rock and metal).
-
Separate reporting of the undiluted and diluted stope-shapes for rock below cut-off (i.e. waste) contained within the skin dilution and contained within the stope design.
-
Reporting the dominant (majority) code, or the proportion and code of the four most common values for one reporting field (i.e. “ranking”).
-
An optional (single line) stope summary file can be output.
-
An optional mined-out model file can be specified to identify the cells inside (and outside) the stope wireframes based on the discretised sub-cells used in the stope optimisation.
-
Support for imperial/metric units can be implemented in supplier user interfaces by using grade and tonnage scaling factors. Note that SSO passes through all values, so units are assumed to be consistent between the model fields and the nominated user parameter values.
Reports can be saved in vendor file type databases (CAE, Deswik, and Maptek) or as a CSV (comma-separated value) text file.
4.5.1 Optional Model Fields
Additional optional model fields can be included in the block model to enable SSO functions such as spatial location modifiers, the inclusion/exclusion of material types within a stope-shape, reporting exclusions, head-grade and others.
The optional model fields are:
-
user_report –to specify additional fields (other than the optimisation and density fields which are automatically reported) from the input model for including in the output report.
-
exclusion1– to set an upper limit to the proportion of a code value for the field in a stope-shape.
-
exclusion2– to independently set an upper limit to the proportion of a code value for a second field in a stope-shape.
-
inclusion– to set a lower limit to the proportion of a code value for the field in a stope-shape (e.g. minimum of resource category 1 that is required to make a stope-shape). Beware of setting the value to 1.0 as this requires the stope to be completely contained within the nominated code, and will not take into other included material at the stope boundaries or numerical rounding errors in the evaluation of the stope.
-
report_exclusion– to exclude the reporting of a code value for the field in a stoping unit e.g. if the code identifies mined out material or air.
-
exclusion_distance– to set an upper limit to the proportion of a code value for the field in a stope-shape, located at some minimum distance from the shape in the transverse direction (e.g. not to mine within a distance from a filled stope).
-
headgrade– a second discriminator that is applied in addition to cut-off. This will allow material to be specified as either ore or waste by using head-grade as a stope volume descriptor.
-
zone_mixing– to restrict the occurrence of multiple code values for a field in a stope-shape. A list of codes is supplied for the zone field, and stopes can be formed for any individual code value, but not a mixture (e.g. if different lenses have different ore types then the stope-shape cannot mix the different ore types).
-
zone_iteration– to optimise the framework origin (U,V) for multiple zones / lodes. The different code values for the zone_iteration field define the spatial location for the different zones / lodes. The Stope Shape Optimiser performs multiple passes for each zone / lode independently (based on U,V step increments specified) and subsequently iterates through all zones / lodes. The outputs are; select the best framework solution for each zone / lode, output all the options or optimise the sublevel spacing for each zone (e.g. 1x20m & 1x10m level spacing versus 3x10m or 2x15m or 1x30m level spacing).
-
mik (multipleindicatorkriging) – to supply pairs of fields for each cut-off grade interval to define the cut-off grade and the proportion above the cut-off grade.
-
conditional_simulation– to define a numeric field for each model realisation.
-
dynamic_anisotropy– fields supplying dip and strike in each model cell that can be used for generating the stope seed-shapes. If supplied, these take precedence over any stope-control-surface wireframe.
4.5.2 Report Codes
The detail report codes produced (in addition to the user selected report fields) are summarised in Table 4.1.
The summary report codes produced in addition to the user selected report fields are summarised in Table 4.2. Note that the summary report provides the total for all RESULT (i.e. 1 and 0 where 0 represents the sub-economic stopes – if selected to be outputted).
A small number of these fields are specific to the Slice Method.
Table 4.1 Detail Report Codes
|
Report Type |
Report Code |
|
STOPE |
Stope name as defined by user |
|
STOPENUM |
Unique stope number |
|
VOLUME |
Volume of shape as defined in REPTYPE below |
|
{mass name} |
Mass of shape as defined in REPTYPE below, default TONNES |
|
{density field} |
Weighted average density of shape as defined in REPTYPE below |
|
{optimisation field} |
Weighted average grade / value (by mass/volume) of the shape as defined in REPTYPE below |
|
CUTOFF |
Optimisation field cut-off value |
|
HEADGRADE |
Optimisation field head-grade value |
|
{optional report fields} |
one or more fields accumulated by weightbymass, weightbyvolume, sum, dominant or ranked |
|
RESULT |
1=Successful Stope |
|
0=Unsuccessful (seed failed to meet stope criteria) |
|
|
PASSTYPE |
1=Full Stope |
|
2=Sub Stope |
|
|
3=Development |
|
|
4=Prism Stope |
|
|
PASSNUM |
0=Prism |
|
1=Full |
|
|
2=SubStope Quad1,3=SubStope Quad2,4=SubStope Quad3, 5=SubStope Quad4, etc. (is dependent on order specified & number specified) |
|
|
N=Development. (equal to the number of sub-stopes specified plus one.) |
|
|
PASSSEQ |
The sequence number (near to far) of the PASSNUM i.e. full stopes and sub-stopes are numbered from 1 as each pass is completed |
|
REPTYPE |
TOTAL=stope-shape content that includes all dilutions (if applicable) |
|
WASTE_FAR=far wall dilution skin content (using global dip convention) |
|
|
WASTE_INTERNAL=waste (portion below cut-off) to make up the stope-shape before near & far dilutions |
|
|
WASTE_NEAR=near wall dilution skin content (using global dip convention) |
|
|
WASTE_TOTAL=total waste (portion below cut-off) within diluted stope-shape |
|
|
WASTE_HW=hangingwall dilution skin content (using local dip convention) |
|
|
WASTE_FW=footwall dilution skin content (using local dip convention) |
|
|
VOID = void or cavity as identified using the "report_exclusion_field" option |
|
|
GROUP |
The wireframe GROUP number. |
|
SURFACE |
The wireframe SURFACE number. All = 1 for shape wireframes, 2= for verification wireframes. No application within current SSO code. |
|
QUAD |
Equivalent to the old IJK value for regular frameworks (QUAD=IJK+1) |
|
WASFRAC |
Proportion (by volume) of sub cut-off rock in shape; (volume of waste within diluted stope) / (total volume of diluted stope) |
|
SLENGTH |
Strike length of stope |
|
SAVGWID/SWIDTH |
Width of stope at centroid position for XZ|YZ, width of stope in XY|YX |
|
SHEIGHT/SAVGHT |
Height of stope for XZ|YZ, Height of stope at centroid position for XY|YX |
|
XSTOPE |
Stope floor-level X centroid-value |
|
YSTOPE |
Stope floor-level Y centroid-value |
|
ZSTOPE |
Stope base / floor minimum Z value |
|
XCENTRE |
Stope centroid X value |
|
YCENTRE |
Stope centroid Y value |
|
ZCENTRE |
Stope centroid Z value |
|
ISFARHW |
Is the "far wall" the "hangingwall" for local/global wall definitions (0=no, 1=yes) |
|
{ranked field}V1 |
value for highest ranked field value |
|
{ranked field}A1 |
proportion (by volume) of total for highest ranked field value using;(A1/(A1+A2+A3+A4)) |
|
{ranked field}V2 |
value for second highest ranked field value |
|
{ranked field}A2 |
proportion (by volume) of total for second highest ranked field value using; (A2/(A1+A2+A3+A4)) |
|
{ranked field}V3 |
value for third highest ranked field value |
|
{ranked field}A3 |
proportion (by volume) of total for third highest ranked field value using; (A3/(A1+A2+A3+A4)) |
|
{ranked field}V4 |
value for fourth highest ranked field value |
|
{ranked field}A4 |
proportion (by volume) of total for fourth highest ranked field value using; (A4/(A1+A2+A3+A4)) |
|
{ranked field} |
weighted average value (by volume) of the ranked field |
|
CONF-PER |
The confidence level for the stope, as a percentage |
|
CONF-MED |
The median value of simulation grades for the stope |
|
CONF-MIN |
The minimum value of simulation grades for the stope |
|
CONF-MAX |
The maximum value of simulation grades for the stope |
Table 4.2 Summary Report Codes
|
Report Type |
Report Code |
|
VOLUME |
Volume of shape as defined in REPTYPE below |
|
{mass name} |
Tonnes of shape as defined in REPTYPE below, default TONNES |
|
ESCOUNT |
Total count of stopes produced |
|
{density field} |
Weighted average density (by mass) of shape as defined in REPTYPE below |
|
{optimisation field} |
Weighted average grade / value (by tonnes) of shape as defined in REPTYPE below |
|
{optional report fields} |
one or more fields accumulated by weightbymass, weightbyvolume, sum, dominant or ranked |
|
REPTYPE |
TOTAL=stope-shape content that includes all dilutions (if applicable) |
|
WASTE_FAR=far wall dilution skin content (using global dip convention) |
|
|
WASTE_INTERNAL=waste (portion below cut-off) to make up the stope-shape before near & far dilutions |
|
|
WASTE_NEAR=near wall dilution skin content (using global dip convention) |
|
|
WASTE_TOTAL=total waste (portion below cut-off) within diluted stope-shape |
|
|
WASTE_HW=hangingwall dilution skin content (using local dip convention) |
|
|
WASTE_FW=footwall dilution skin content (using local dip convention) |
|
|
VOID = void or cavity as identified using the "report_exclusion_field" option |
4.5.3 Waste Reporting
The waste reporting definitions in the Version 2 implementation are:
-
Waste_Total. Is reported using the defined cut-off. This is the portion of rock contained within the diluted stope-shape that is below the cut-off (e.g. 500t of the 10,999t diluted stope-shape is below the cut-off). The grade of the below cut-off rock is the mass weighted average grade.
-
Waste_Internal. Is reported using the defined cut-off. This is the portion of rock contained within the undiluted stope-shape that is below cut-off i.e. this reports below a cut-off. The grade of the below cut-off rock is the mass weighted average grade.
-
Waste_Near, Waste_Far, Waste_HW, Waste_FW. Is not reported using the defined cut-off. This is the total mass of rock contained within each dilution skin defined (i.e. near, far, hangingwall, footwall). The grade of the rock within each dilution skin defined is the mass weighted average grade.
With these definitions the Waste_Total does not equal the sum of the Waste_Internal + Waste_Near/Waste_Far/Waste_HW/Waste_FW because only the Waste_Total and Waste_Internal report rock below the defined cut-off while the others report all rock.
The WASFRAC field is defined as; (volume of rock below cut-off / total volume of the diluted stope-shape). Note that for the Prism Method there are no dilution skins involved, so it is just the total stope-volume.
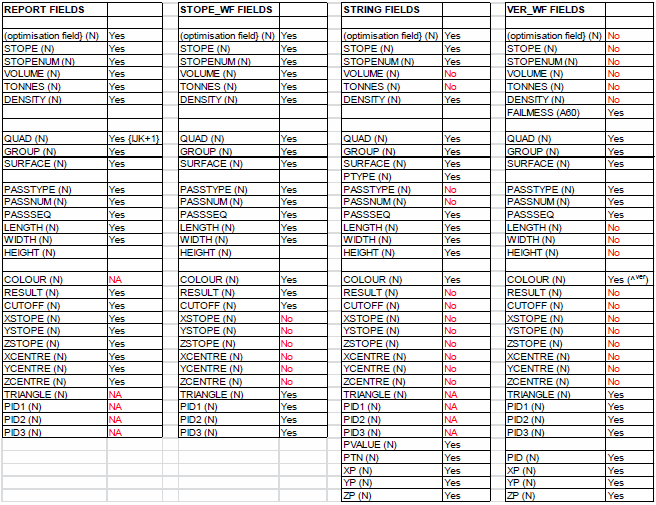
4.5.4 File Field Names
All the reported fields (detail report codes above) are essentially reproduced in the stope-shape wireframe and stope string files. The verification files however exclude these fields and report only GROUP, SURFACE, QUAD, PASSTYPE, PASSNUM and FAILMESS (failed message) fields. The field comparisons are summarised in the following.
Table 4.3 File Field Names
4.5.5 Rename Mass Field
The stope report mass field may be renamed and factorised.
An example use for this function is to change the field TONNES to say KTONNE and multiply the original TONNES field by a 0.001 factor to derive “kilo-tonnes” or “thousands of tonnes”.
4.5.6 Mined Out Model
A mined out model can optionally be output to identify the portion of the model that is mined, is part of a pillar or is otherwise unmined. The output model represents the sub-cells after the discretisation process, split according to the portion that falls within the stopes and the pillars.
The mined out model has values of 0 or 1 in the MINED and PILLAR fields to indicate exclusion or inclusion. The MINED field name can be replaced with a user defined field name. There is also the option to output only the MINED=1 discretised sub-cells only.
It is useful to review the mined out model to assist understanding what the discretisation process is doing. The mined out model may also have many other downstream uses. Beware that the mined out block model can be much larger than the input block model because it provides the discretised model cells. The mined out model was primarily designed for test areas or use with validation_test_cell quadrilaterals.
4.6 Stope Naming
Stope-names (alphanumeric type) can be generated by concatenating component parts (in any combination) of up to a combined total of 40 characters. The stope-name could typically be used to spatially locate stopes (e.g. level position, block position, extraction sequence, etc.) or to categorise as a stope type (e.g. primary or secondary, high grade/value or low grade/value, wide or narrow, measured category, etc.).
Note that the stope-names should be defined so as to be unique. For example, using component parts that describe the mine-name followed by floor-level would result in all stopes on any particular level to have the same stope name.
Each part will need to have some or all of the following parameters specified:
· (fixed) length in characters,
· number of decimal places (if numeric),
· justification (left, centre, right),
· field name
· pad character
The component parts are described in the following.
4.6.1 Reporting Field
A reporting field value part can be any of the nominated fields reported from the input block model or contained in the detailed output report as summarised in Table 4.1. This could typically be any one of:
· STOPENUM,
· QUAD, PASSTYPE, PASSNUM, PASSSEQ,
· XSTOPE, YSTOPE, ZSTOPE (central coordinate at floor position),
· XCENTRE, YCENTRE, ZCENTRE (centroid coordinate)
· SLENGTH, SHEIGHT, SAVGWID (or equivalent for horizontal frameworks),
· CUTOFF, RESULT,
· ISFARHW, (is the far wall the hangingwall - True/False - 1 or 0),
· Model evaluation fields (e.g. Au Grade, NSR value, Zone, Rescat, etc.).
4.6.2 Internal Field
These are automatically generated field values that can be used from the following list:
· stope_type (outputs one of ‘Full’, ‘Sub’, ‘Dev’)
· stope_orientation_plane
· u_local_avg | v_local_avg | w_local_avg | x_world_avg | y_world_avg | z_world_avg
· u_local_min | v_local_min | w_local_min | x_world_min | y_world_min | z_world_min
· u_local_max | local_max | w_local_max | x_world_max | y_world_max | z_world_max
The (u,v,w)_local and (x,y,z)_world fields will be identical if the framework is unrotated, but (x,y,z)_world are required to provide world coordinates for rotated frameworks..
4.6.3 Fixed String
This can be any user defined text e.g. “East_”, “MyProject-“, etc. Commonly used as a separator between other parts (e.g. “_”, “-“, etc.).
4.6.4 Position Counter
This is a generated value that represents a spatial location.For regular model frameworks, 'position_counter' evaluates the position of the stope in the framework. It advances forward/backward from the start/end along the specified 'axis' direction, counting the number of "steps" in the stope framework. It uses the supplied "start" value and applies the number of steps (using the "step size") to define a value to assign for each stope based on its framework position along the defined axis (U|V in the stope orientation plane and uses the PASSSEQ field value on the W axes), or in the reverse direction. The start value can be numeric or letter (i.e. 'number_count', 'letter_count'). Letters can be a mixture of upper and/or lower case, and the increment restricted to the supplied case.
The PASSSEQ field is used to number full stopes, substopes in sequence from the near to the far side of the framework.
If an XZ framework has sections along the U-axis of 1000, 1100, 1200, 1300, 1400, 1500 and full stopes generated between these sections, then the value generated for the position counter for the following cases would be:
· start at minimum, number count, start = 50, increment = 100
50, 150, 250, 350, 450
· start at maximum, number count, start = 450, increment = -10
50, 150, 250, 350, 450
· start at maximum, number count, start = 50, increment = 10
450, 350, 250, 150, 50
· start at minimum, letter count, start = A, increment = forward
A, B, C, D, E
· start at maximum, letter count, start = Z, increment = back
U, V, X, Y, Z
· start at maximum, letter count, start = A, increment = back
E, D, C, B, A
If the letter count exceeds A-Z, then multiple letters can be employed with AA incrementing to AB, AC,.., AZ, BA etc. Aa would increment to Ab, Ac,..Az, Ba if lowercase was used for the letter start to signify case sensitivity.
4.6.5 Expression List
An 'expression_list' defines a collection of one or more ('expression', 'value') pairs. Each expression refers to field names and/or constants connected by relational operators. Expressions are evaluated in turn for the stope until the first match is found, and the associated "value' from the (expression, value) pair is used for the 'part'.
For the syntax of the expression text, see the Filter Expression section.
A simple example for using an expression list for naming stopes based on grade range would be as follows:
|
Expression |
Value |
|
"field AU GT 10.0" |
"HG" |
|
"field AU GT 5.0" |
"MG" |
|
"field AU GT 2.5" |
"LG" |
The order of the expressions is important as the first expression satisfied will be used to assign the Value.
4.7 Model Fields - Exclusion, Exclusion-Distance, Inclusion, Report Exclusion and Mixing
Fields can be supplied in the block model and coded to indicate areas that might be included or excluded to a user defined proportion in stopes.
Up to two independent exclusion fields can be supplied.
An exclusion-distance field can be supplied where stopes must be more than a set distance away.
If stope optimisation is to be restricted to a specific zone then an inclusion field can be specified. The stope must be wholly or partially be within the inclusion zone, depending on the proportion set.
A model report-exclusion field allows mined out material or voids to be ignored in the stope evaluation.
A mixing field and associated values can be supplied to control mixing of material with different attributes. If a model has multiple ore types then stope-shapes are generated to not allow mixing of the ore types (as designated in the ore type field). No two field values from the list specified can be found in a stope.
4.8 Multiple Optimisation Criteria
A single field is supplied for optimisation, either to maximise value or metal.
Filter expressions provide a way of supplying additional criteria. Filters are applied to the processing of the seed and annealed stopes. The filters allow evaluated model variables to constrain the production of stope-shapes e.g. RQD criteria, penalty element criteria, resource category requirement, etc. as detailed in filter text sub-section.
4.8.1 Filter Text
Filter text(i.e. filter expression) can be used to control the generation of the stope seed and subsequent stope annealing process. The stope seed and annealing process must fulfil the filter text requirement to produce a stope-shape.
For example, to only generate stopes that meet a value, range of values or range of criteria e.g. “RQD>70”.
Another example could be that 90% of the stope-shape must contain measured resource category (e.g. RESCAT=1). By using the internally generated “ranking” report fields (up to 4 values) for the RESCAT field and then using the filter text “CLASSV1=1 and CLASSA1>=90.0”. Note that in this example it is only necessary to test the first ranked field if the percentage is 90.0 because the second ranked field could never have a value of 90.0. If the limit was thirty then the expression would need to be “(CLASSV1=1 and CLASSA1>=30.0) or (CLASSV2=1 and CLASSA2>=30.0) or (CLASSV3=1 and CLASSA3>=30.0)”. The fourth ranked field need not be tested as it could never have a percentage greater than 30.0 while still being the fourth ranked field.
An expression may be either a relational expression or a pattern matching expression.
4.8.2 Relational Expression
The syntax of a relational expression is:
[FIELD] <fieldname> <operator> [CONSTANT] <value>
or [FIELD] <fieldname> <operator> [FIELD] <fieldname>
or [CONSTANT] <value> <operator> [FIELD] <fieldname>
The keywords FIELD and CONSTANT are optional, and need only be specified where necessary to avoid confusion (e.g. "ROCKTYPE=FIELD T2" or ROCKTYPE=CONSTANT T2").
Each expression refers to field names and/or constants connected by relational operators. Any of the six relational operators listed as follows may be used.
· GT, Greater than
· GE, Greater than or equal to
· EQ, Equal to
· LT, Less than
· LE Less than or equal to
· NE, Not equal to
The alternative method of expressing these (i.e. >, >=, !=, etc.) have been removed to avoid conflict with the XML syntax.
4.8.3 Pattern Matching Expression
The syntax of a pattern matching expression is:
<fieldname> MATCHES [REGEXP] <pattern>
If the keyword REGEXP is missing, a "pattern" may consist of literal characters to be matched, or one of the following elements:
· ? Any single character
· Wildcard. A group of zero or more characters
· [...] Any one of the characters enclosed in the square brackets. The short hand notation "a-z" means any lowercase letter; refer to the examples below for more details.
· [^...] Any character except one of these
The special meaning of a character (e.g. "*") is lost if the character is preceded by "\", hence to match a literal "*", use "\*".
Quotes (double or single) may be used to enclose patterns if desired.
If the keyword "REGEXP" is used, the pattern specifies a full regular expression.
Regular expressions allow advanced users to make more complex selections than are possible by using the pattern elements specified above.
A regular expression in PICDIR may contain the following elements.
· % Matches the beginning of the file or field name
· $ Matches the end of the file or field name
· Zero or more occurrences of the preceding pattern element.
· ? As above
· [...] As above
· [^...] As above
4.8.4 Concatenation of Expressions
The result of a pattern matching expression is either TRUE or FALSE.
Any result may be inverted by preceding the expression by the keyword "NOT" (e.g. "NOT BHID MATCHES RHD*").
Two expressions may be joined together by "AND" or "OR" operators. The result is another expression.
The "AND" operator has higher precedence than "OR".

