Check/Remove Duplicates
Use this option to check for and resolve the duplicate records in a samples database. The option uses the standard data fields for sample position (X, Y, Z) to determine duplicates.
On the Geology menu, point to Sampling, then click Check/Remove Duplicates.
Specification file
Use the drop-down list to select the specification file if it is in the current working directory, or browse for it in another location by clicking the Browse button. A new file may also be created by typing the name of the new file in the textbox and clicking the New button.
-
 Browse
Browse -
 New
New -
 Save
Save -
 Save as
Save as
Samples Database
Choose one of the following:
Isis File
Select the file from the drop-down list, or click Browse... to select a file located in a different folder.
ODBC Link
Select a Design file from the drop-down list.
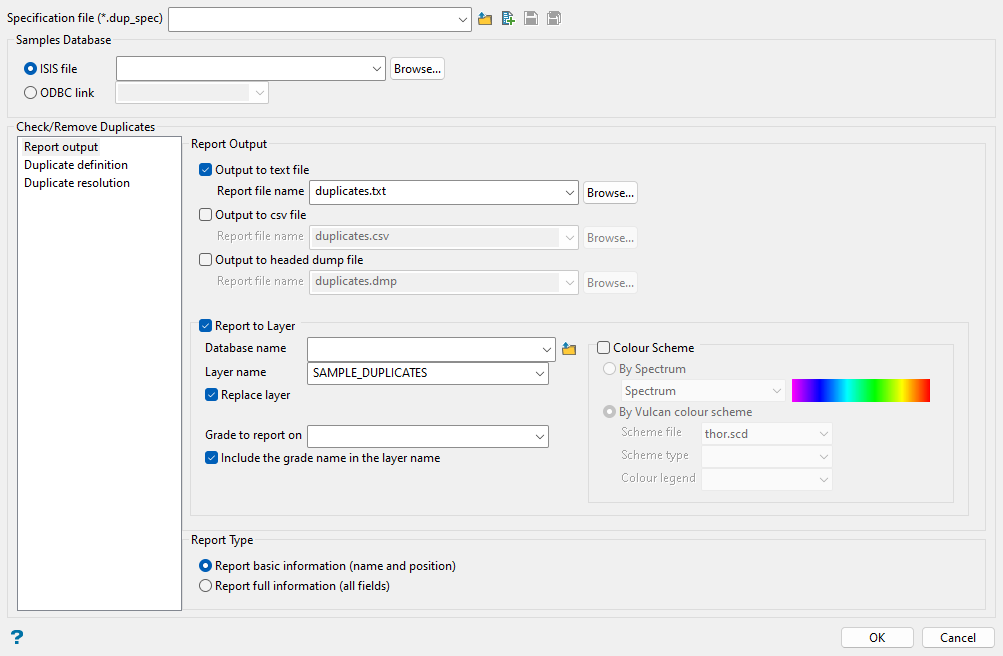
Report Output
This will list the duplicates found, along with the settings used produce them. The data reported is the same for all three file formats: text file (.txt), CSV file (.csv); and dump file (.dmp).
Select one or more of the output options.
Output to text file
In the text file reports, the duplicates will be grouped in twos, threes, fours, etc. according to how many duplicates were found matching the criteria. The groups will be separated by a blank line. The header of the report will detail the settings used in searching for duplicates. The entries consists of:
-
Duplicate: An internal reference count of the number of duplicates found.
-
Key: The DB key under which each duplicate was found (see the Duplicate definition section of the panel for more details).
-
Line: The line number in the key on which the duplicate occurs. It corresponds exactly with the line number seen in the Isis Editor if this data displays in that editor for examination/modification.
-
Distance: The second and subsequent records in a duplicate group will show the distance from the previous item in that group.
-
Data: All following fields are data from the duplicate record, under the headings of their field name on the DB. See the Report Type section below for a description of what will be shown here.
Output to csv file
The CSV report contains much the same information, but rather than separated the duplicate groups with a blank line. The CSV report contains none of the settings used to derive the report data, there being no header on a CSV file in which to store this information.
Output to headed dump file
The DMP dump file report provides that same data in a form which can be utilised by the Maptek report generation utility (now only available through the Advanced Reserves Editor reporting facility, but still functional with this type of file). The dump file report contains the settings used to derive the report data in the comments at the top of the header.
Report to Layer
This option allows to save duplicate samples to a layer with colour schemes.
Layer name
Select a layer from the drop-down list for the duplicate samples to be saved. Users can choose to replace the layer by selecting the checkbox below.
Grade to report on
Choose a grade from the drop-down list. Users can choose to include the grade name in the layer name by selecting the checkbox below.
Colour Scheme
The duplicate samples can be colour coded by choosing one of the following schemes:
-
Colour by spectrum: Select this option to colour by spectrum. This means that the colour spectrum is stretched over the values. Use the drop-down list to select the desired spectrum.
If you select the Between two RGB values option, you will need to nominate two colours to stretch over the values. For example, if you select red and blue, then the small values would be red, the middle values purple, and the large values blue. The colour of the middle values is an average of the two chosen colours.
-
By Vulcan colour scheme: Select this option to colour by using a Vulcan colour scheme. This option is similar to Colour by spectrum in the way it varies by the values, but it does so by the customised colour scheme that you define. Use the drop-down menus to select the Scheme file, Scheme type, and Colour legend.
Report Type
The report type can be set to report either basic or full information.
The basic information reports are demonstrated in the examples shown above, where the standard columns are displayed followed by only those data fields from the duplicate samples record which define the position of the sample. In these examples those fields are called X, Y, Z.
Either of the report types can be used to easily identify the duplicate records in the sample database when using the Isis editor application. So that they can be manually checked and rectified, if required. Obviously, it is easier to use the automatic resolution of these duplicates offered by this software.
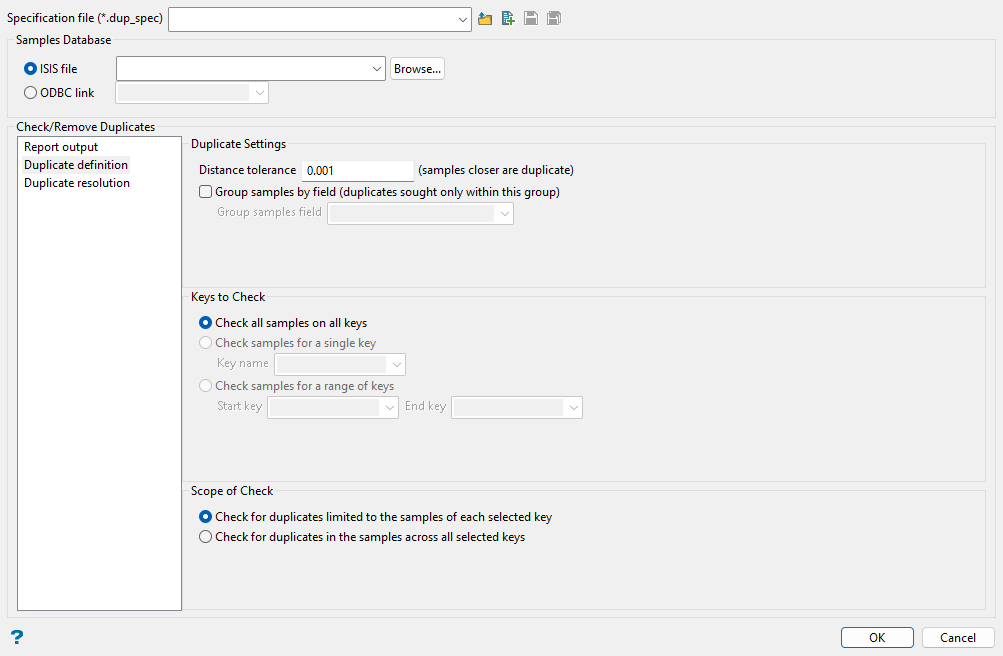
The Duplicate definition section describes what comprises a duplicate and the range and scope of the search for duplicates.
Duplicate Settings
Distance Tolerance
A duplicate samples record is defined as one which is closer, in 3D, to another samples record than a prescribed tolerance. The default value for this tolerance is 0.001 but this value can be changed if required (minimum setting 0.0001, maximum undefined).
Group samples by field
By default, duplicated are sought across all records in a single key. However, if there are subcategories of data in that key, it is possible to restrict the checks to these subcategories using the Group samples by field option. To use this, select the check box and pick the field name which describes the categorisation.
Note: For this type of selection to work, the assumption is made that the subcategories occur in sequence in the Key (if not, it may be necessary to pre-sort the data with the group field as the primary key).
Keys to Check
By default, checking is carried out on a key by key basis across all keys. However, the range of the check can be limited if required. Limiting may be either to a single key, or across a range of keys. If a range check is used, the start and end are inclusive.
Scope of Check
By default, the scope of checking is limited to searching in each selected key separately, However, checking can be performed across all of the selected keys, so that if a sample position from one key is duplicated in another key, this will also count as a reported duplicate.
Note: Using the second option as well as grouping by field is not advised -- unless you know the data will support it. Having selection in a group can cancel out the request of checking across all keys when there are regular group changes in a key. The change of group defines the end of a set of records to check.
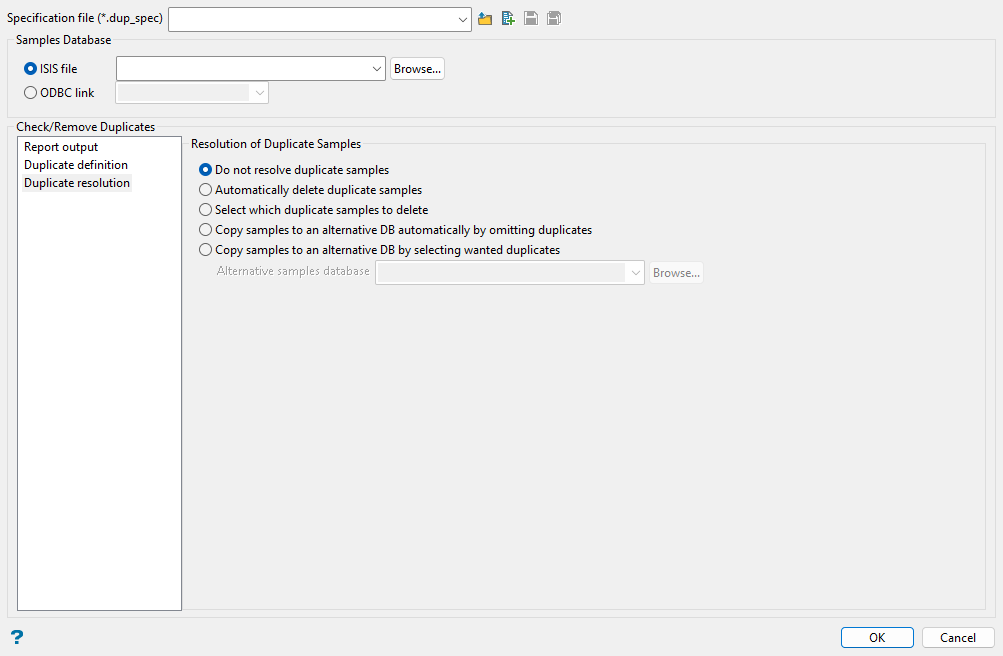
Use the Duplicate resolution section to resolve any duplications that are discovered.
Do not resolve duplicate samples
By default the software does not attempt to resolve any duplicates found, it just reports them.
Automatically delete duplicate samples
If this option is selected, the software will automatically select which samples records to delete from the database in order to remove the duplication. It does this by selecting to retain the best record only from each duplicate group (see the report section for what comprises a duplicate group). The best record is defined as the record from the group which has the most fields containing a value. If more than one record contains the same maximum number of set fields, then the first of these will be selected.
Select which duplicate samples to delete
In this option, after finding duplicate records, the software will present a selection list containing all of the duplicate records to allow a manual selection of which ones to retain. This selection list will have the best records already selected by default (see the Automatic Deletion section for a description of what comprises a best record).
The information presented is along the same lines as that reported in the report file(s), although this will always display all of the data fields in the record after the first standard five fields.The default selection of the best records is shown in blue -- the selected records are the records which will be retained - the rest will be deleted.
The record selection can then be changed in the usual manner with selection lists; in brief:
-
Selecting a line will clear the entire selection and replace it with that line only.
-
Selecting a line while holding down the Control key (CTRL) will invert the current selection of that line only.
-
Selecting two lines while holding down the Shift key will select all lines between and including those lines.
There are a number of buttons to aid in bulk changes:
-
The Clear Selection button will remove all selection from the list -- no duplicates will be retained all displayed records will be deleted.
-
The Invert Selection button will reverse the current selection displayed.
-
The Default Selection button will reinstate the selection of the best records. This is useful if a selection is accidentally made without holding the CTRL or Shift key and thus wiping out the selection.
Selection of all records can be made by typing CTRL+A, or from the right-click context menu on the list control widget.
Deletion of the unselected records will be performed when the OK button is presses. Pressing Cancel will abort any deletion.
Copy samples to an alternative DB automatically by omitting duplicates
Selecting wither of the copy options will enable the Alternative samples database field at the bottom of the list of options. The name of an existing DB or a new DB name may be entered or selected from the browse. It is not necessary to enter the full name, the extension will be added automatically (the structure of the new DB will be identical to the original).
Note: Existing databases will be overwritten, not added to. If is not possible to offer the option to copy to an ODBC database, because it is not possible to create an ODBC database externally to the actual database software.
This option will automatically copy the existing data base to the alternative data base name selected. The data from all keys will be copied, not just the limited selection of keys made in the key selection section (if such a selection was made). In this automatic copy, only the best records from any duplicate groups will be copies, and the others in the group omitted from the copy. (See the Automatic Election section for a description of what comprises a best record).
Copy samples to an alternative DB automatically by selecting wanted duplicates
Selecting either of the copy options will enable the Alternative samples database field at the bottom of the list of options (See the Automatic Copy section for a description of the Alternative database).
This option behaves like the Manual Deletion option in that it offers a selection list of records (with the best selected) to define which records from the duplicates are to be copied across. See the Manual Deletion section for a description of how to use this control.
On pressing OK from the selection list, the full DB will be copied to the alternative DB excluding those duplicate records not selected.
Click OK.

