Calculation Rules
This section provides the system with the rules for creating, combining, averaging and setting the values of the attributes. There is considerable similarity between this and the similar sections of the ‘advanced’ tab of the Legacy Grade Control ‘Blast Preferences’ panel.
Instructions
On the Grade Control menu, point to Setup, then click Calculation Rules to display the following interface.
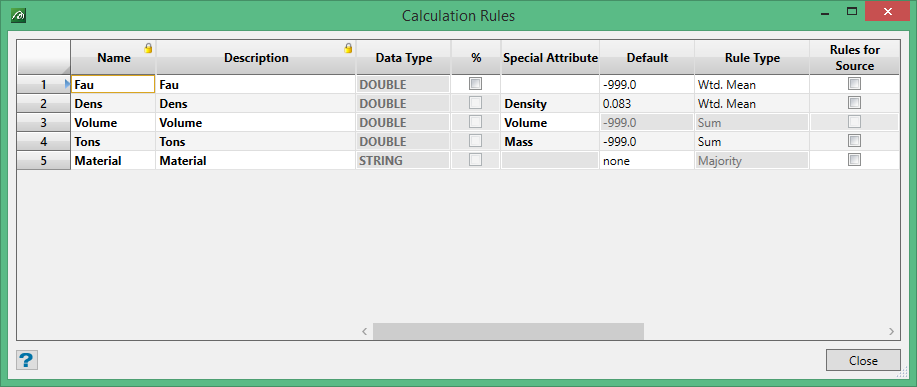
We have attempted to place the columns across the panel in as logical an order as we could, so there may be some perceived differences in order between this and the Legacy setup. With this in mind the description of the columns in the following sections will be made in this order.
Column width and panel size may both be altered by the user for ease of viewing/editing items in the table on this panel.
Note: Rows may not be deleted from this table. If attributes are not required, or new attributes added, this must be done on the Data Source Correlation panel.
Name & Description
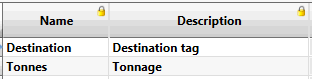
These columns contain the name and description of the attributes in use. The list of attributes will be in the order of the table decided in Data Source Correlation and will be the versions of these values decided upon in that table. So, they are read-only fields in this panel.
Data Type
This column indicates the data-type of the attribute in question.
Where the attribute is one of the fields in the data sources and will be used as a source item for calculation, or sink item for result in the database, then this data type has been predefined. In this case, the cell in the table will be disabled, because the setting cannot be changed.
For any attributes added as temporary/intermediate variables in the Data Source Correlation table, these cells will be enabled and initially the values will be set to UNDEFINED by default.
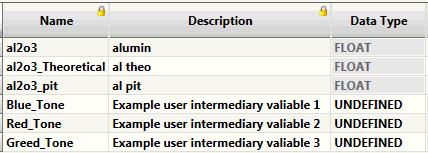
These values MUST be set to their desired type before specification setup is deemed to be complete and valid. The field type for this cell is a combo-box containing the understood data-types, one of which must be selected for each undefined item.
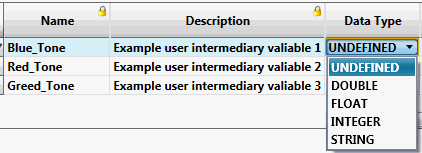
Note: These values are under local control and will be shown in the appropriate language for that locale.
Percentage (%)
The Percentage column (just shown by the % symbol to save space) is a flag column to indicate to the system whether a numeric variable represents a percentage value. This is required to ensure that statistical calculations are performed correctly on percentage values.
These cells will be disabled automatically for STRING type attributes and Special Attributes (which are described in the next section) where a percentage flag setting is not appropriate.
Special Attribute
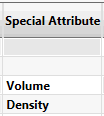
Some attributes have ‘special’ defined meanings for Grade-Control – particularly for reporting purposed. Currently, three types of variables are understood as having ‘special’ functions – these are Volume, Density and Mass.
The new Grade Control is ‘localised’. Thus, we cannot simply rely on the names of these variables to identify them (as Legacy Grade Control does) because their names in, for example, Chinese (or even Spanish) will not be recognised. So, in the spirit of making everything explicit in new Grade-Control, if these variables are being used they must be identified explicitly.
These fields, again, are combo-box fields from which the appropriate special item setting required can be selected. At present, only Volume, Density and Mass are available to be picked and can be assigned to any appropriate field in the attribute list irrespective of its actual name. Appropriate fields and any ‘real’ number type (FLOAT or DOUBLE).
Only one field at a time may be selected for each of these special items. If a second attribute is selected as a special item, the system will automatically remove that special setting from the first.
The Density and Mass items are optional. But there must be an item selected as the Volume value. This item will have any a rule type set to ‘Sum’ and other sort of ‘rule’ type setting disabled. It will also be given an unchangeable default value of zero.
If a Density item is selected it MUST be given a sensible default value; i.e. a number greater than 0 and less than 10.
Default
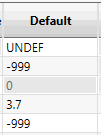
The default values are used to initialise the attribute values for every item in the data source before reading and every item in the output data before calculation (and writing). They are also used to provide the block-model default values for generated block-model creation, and the map-file default values for compositing (which happens for both generated block model creation and grade estimation directly from external drill-hole or internal blast hole data).
The only value automatically set by the Grade-Control system is for the special attribute ‘Volume’ where the value will be set at zero and the cell disabled so that it cannot be changed.
The only other ‘required’ value is for the special attribute ‘Density’ where a geologically sensible value MUST be given – without it the specifications will not be considered complete nor valid.
While none of the other attributes are required to be set by the user, it is perhaps advisable to set them. It makes it easier to recognise where data items are missing if the user’s own default value has been set.
If no default value has been ascribed to an item on this panel or the default value provided is invalid (e.g. -99 to a STRING item or “unknown” to a NUMERIC) then system defaults have to be be applied automatically for the missing items for both block-model and map-file generation. This is the same behaviour as Legacy Grade-Control and is required by the Vulcan™ systems used for these functions. These system applied defaults will be
-
-999 for all numeric items
-
“undef” for string variables in the block-model (without the quotes)
-
“” for string variables in the map-file (i.e. an empty string)
Note: The provided panel defaults will still be used for initialising attributes, the system values only being used for block-model and map-file where needed.
Rule Type
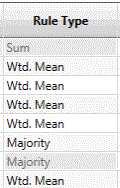
This column provides the simple settings for how data will be accumulated for an attribute on the grade-block from the source-item(s). For example, a grade-block will probably encompass a large number of block-model blocks or blast holes. To determine a value for the grade-block from all of the source items will most likely require a weighted average (Wtd. Mean – the default setting for this field).
If a more complex mechanism is required for setting the grade-block value, an Assignment Rule can be set for the grade-block – in which case this cell for the attribute will be disabled (as being no longer applicable). [Note: this modality of the panel is intended as an improvement over the Legacy version, where it is hard to determine what settings apply – here we have tried to be more explicit]
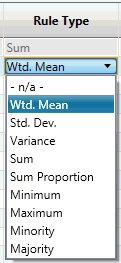
This cell type is a combo-box containing the available ‘simple’ rule types that can be used for data accumulation.
The default setting for all source attributes will be ‘Wtd. Mean’ (weighted mean), with the exception of the special attribute ‘Volume’ which will be the unalterable ‘Sum’.
The default setting for the temporary/intermediate attributes will be the not-applicable ‘- n/a -’, because these items have no source and it is assumed (required) that they have an assignment rule to be used. It is not valid to set any source attributes to ‘- n/a -‘.
The available settings for the ‘simple’ rules have been extended from the Legacy Grade-Control options with the addition of ‘Sum Proportion’, ‘Minority’, and ‘Majority’. These will now be discussed briefly below.
Weighted Mean (Wtd. Mean)
Applicable to numeric continuous value attributes, a weighted mean value will be calculated using the weighting rules provided in the weight rule columns – Block Model Weight Rules for block-model data (same rules for both pre-built and generated block-models) and Holes/Samples Weight Rules for both external drill-hole or internal blast hole data.
If ‘Wtd. Mean’ is set for a STRING attribute, no error is given, but the value set for the attribute will be a blank text value. Likewise, using ‘Wtd. Mean’ for categorical (discontinuous) numeric data (e.g. INTEGER category flags) may not provide the expected (or indeed a meaningful) result. This is a case of the user having to think about the statistical outcome they require.
Standard Deviation (Std. Dev.)
Applicable to numeric continuous value attributes, the standard deviation of the weighted mean value will be calculated – using the weighting rules as for ‘Wtd. Mean’.
Behaviour when used on STRING attributes and other categorical data as for ‘Wtd. Mean’.
Variance
Applicable to numeric continuous value attributes, the variance of the weighted mean value will be calculated – using the weighting rules as for ‘Wtd. Mean’.
Behaviour when used on STRING attributes and other categorical data as for ‘Wtd. Mean’.
Sum
Applicable to numeric continuous value attributes, the simple sum of the values is made from each data source item – irrespective of any weighting or proportion of the data. Should only really be used on data items from the source when this type of weighting has already been calculated into the source values; e.g. summing a mass variable from the blocks of a block-model.
Behaviour when used on STRING attributes and other categorical data as for ‘Wtd. Mean’.
Sum Proportion
This allows the proportion of a source item enclosed within the grade-block to be applied to the sum. For instance, where a block-model block is only partially included within the grade-block solid (e.g. 25%), only that proportion of the value will be summed.
Applicable to numeric continuous value attributes, the proportional sum of the values is made from each data source. As with the simple ‘Sum’ this should only really be used on data items from the source when this type of weighting has already been calculated into the source values; e.g. summing a mass variable from the blocks of a block-model.
Behaviour when used on STRING attributes and other categorical data as for ‘Wtd. Mean’.
Minimum
Applicable to all data-types. Sets the attribute value to the value of the minimum source item
encountered. For STRING data this will be the minimum canonical value.
Maximum
Applicable to all data-types. Sets the attribute value to the value of the maximum source item encountered. For STRING data this will be the maximum canonical value.
Minority
Applicable to categorical data types (STRING and INTEGER flags). This sets the attribute to the value of the value of source item category encountered LEAST often in the source data.
Whilst it would be meaningless to use this with real data types (DOUBLE and FLOAT) this can be done (to allow for numeric categories mistakenly being passed from a DB as a real value). Real values are converted to their nearest integer – and this value is used as the category.
Majority
Applicable to categorical data types (STRING and INTEGER flags). This sets the attribute to the value of the value of source item category encountered MOST often in the source data.
While it would be meaningless to use this with real data types (DOUBLE and FLOAT) this can be done (to allow for numeric categories mistakenly being passed from a DB as a real value). As with Minority real values are converted to their nearest integer – and this value is used as the category.
Rules for Source and Rules for Grade-Block
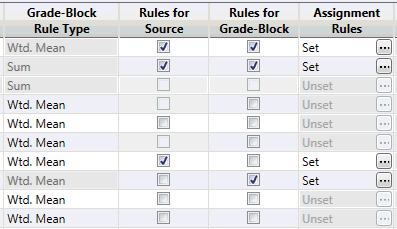
These two check-box columns, the titles of which in full would be ‘Apply Assignment Rules for Source’ and ‘Apply Assignment Rules for Grade-Blocks’, have been kept short for appearances sake.
-
-
The modal behaviour controlled by these fields can be seen in the panel screen-shot above.
-
The Assignment Rules column field for a row remains disabled until either or both of these check-boxes is ticked (because it is not required until rules are to be applied somewhere).
-
If the ‘Rules for Grade-Blocks’ check-box is ticked, the Grade-Block Rule Type column field for that row will be disabled (because now the Assignment Rules will be applied rather than the ‘simple’ rule).
Note: If the Assignment Rules field is enabled, then rules must be set for that attribute for the specifications to be considered complete and valid.
Rules for Source
By ticking this column, the user indicates that the Assignment Rules are to be performed on the source data prior to the accumulation of values to the grade-block. For instance, if there is a derived data-item (e.g. Destination Tag) which is decided by a grade variable (e.g. Iron grade) then this value can be derived for each source item before being used in data accumulation to the grade-block (where, for example, the item could be used in another item’s rule or as a Majority/Minority setting).
Rules for Grade-Block
By ticking this column, the user indicates that the Assignment Rules are to be performed for the accumulation of values to the grade-block. For instance, where there is a derived data-item (e.g. Grade-block feed bin) which is decided by the grade-block’s grade variables (e.g. Iron grade, silicate impurities, etc.) then this value can be computed using the rules after the grade variables have been accumulated. If necessary, the same rules can be applied to both the source items and the grade-block accumulations. This might be wanted, for example, where derived values are to be updated in the blast hole data as well as computed for the grade-block.
Assignment Rules
The Assignment Rules cell on a row will only be enabled if one or both of Rules for Source or Rules for Grade-Block check-boxes have been ticked.
If the Assignment Rules cell is enabled then rule(s) must be set for that cell. The cell will contain the words ‘Set’ or ‘Unset’ to indicate the current status of the rules for that row.
Note: Assignment Rules are never set for the special attribute ‘Volume’, because the explicit volume of the item is always used. So this cell will always be disabled.
Setting the Assignment Rules
Selecting the button with the ellipsis on an enabled Assignment Rules cell will cause the edit/display panel for the rules on that row to be displayed.
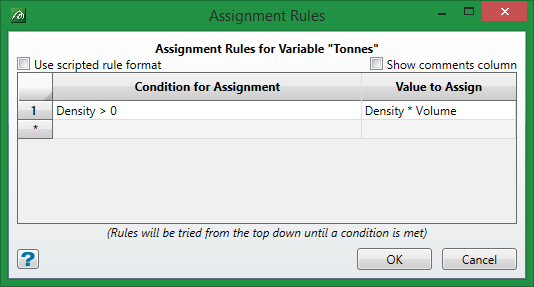
There have been a number of changes and improvements made to the Assignment Rules setting with the new grade control. Rules can be set using either the standard condition/value form (similar to Legacy GC) or via the new, more flexible, programmatical rule format.
The standard assignment rules panel will be displayed by default when entering assignment rules for the first time (as shown above, but with no data in it). The format of this is
if this ‘Condition’ then use this ‘Value’
Programmatical Rules
By ticking the check-box ‘Use programmatical rule format’ the rules panel switches to a text-editor form which allows for programmatical rules to be written.
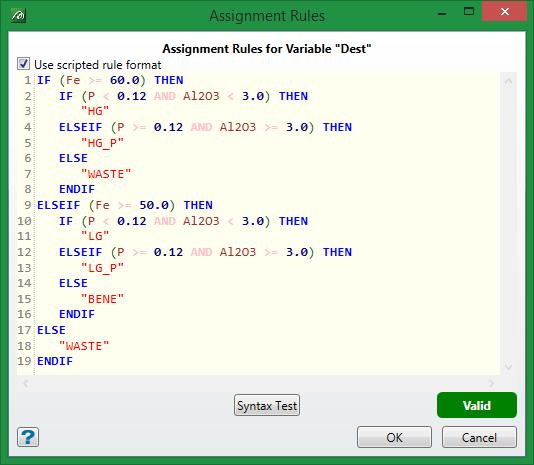
A more detailed explanation for Assignment Rules is available here .
Block Model Weight Rules
This column will only be enabled if either or both of pre-existing source block-model or generated block-model have been specified in the Data Source Definitions. This allows the user to specify how values are to be weighted from the block-model when used for any of weighted Grade-Block Rule Types (Wtd. Mean, Std. Dev., and Variance).
A more detailed explanation for Assignment Rules is available here .
Estimation ID
This column will only be enabled if generated block-model has been specified in the Data Source Definitions.
A more detailed explanation for Assignment Rules is available here .
Holes/Samples Weight Rules
This column will only be enabled if one of internal blast holes, external drill-holes or external samples have been specified as the source on the Hole/Sample Source Tab in Data Source Definitions. This allows the user to specify how values from the source are to be weighted when used for any of weighted Grade-Block Rule Types (Wtd. Mean, Std. Dev., and Variance).
A more detailed explanation for Assignment Rules is available here .
Update in Hole
This column will only be enabled when internal blast holes has been specified as the source on the Hole/Sample Source Tab in Data Source Definitions. Only those attributes which are correlated with the blast hole data will be enabled.
This behaves exactly as in Legacy Grade-Control, updating fields in the blast hole data on the grade control database.
Reconciliation Function and Reconciliation Weight

We will deal with these items together, as they are linked. Their function and behaviour is exactly as with Legacy Grade-Control. These columns will only be enabled if all of the pre-requisites for reconciliation are in place:-
-
-
Reconciliation block model(s) defined in Block Models tab of Data Source Definitions.
-
Reconciliation option selected in the grade control database setup.
-
Reconciliation records are defined in the grade control database setup.
-
Reconciliation data is correlated in the Data Source Correlation setup.
-
Only the cells on the rows that are correlated to the reconciliation records will be enabled.
These settings and the functionality are essentially the same as for Legacy Grade Control. You will notice that in GC V2 these columns are in the reverse order from the Legacy ‘Advanced’ tab, as this seems a more logical arrangement.
Reconciliation Function
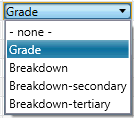
The reconciliation function can be selected from the combo-box cell on that column, as shown to the left. The available options are as shown. The three levels of breakdown are explicitly given here – in Legacy GC it was not obvious in what order breakdown variables were to be applied (presumably row number sequence) – here we specify explicitly the required order.
Reconciliation Weight
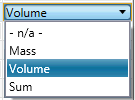
The reconciliation weight can be selected from the combo-box cell on that column, as shown to the left. The available options are the same as those in Legacy GC.

