Sequential Gaussian
Use the Sequential Gaussian option to perform conditional or unconditional Gaussian simulation. Gaussian simulation will populate a grid of nodes in a block model that, if performed correctly, will honour the data distribution and the spatial correlation. Multiple realisations can be performed at a time. Each realisation will be stored in a separate block model variable.
Instructions
On the Block menu, point to Simulation, then click Sequential Gaussian.
Simulation Parameters
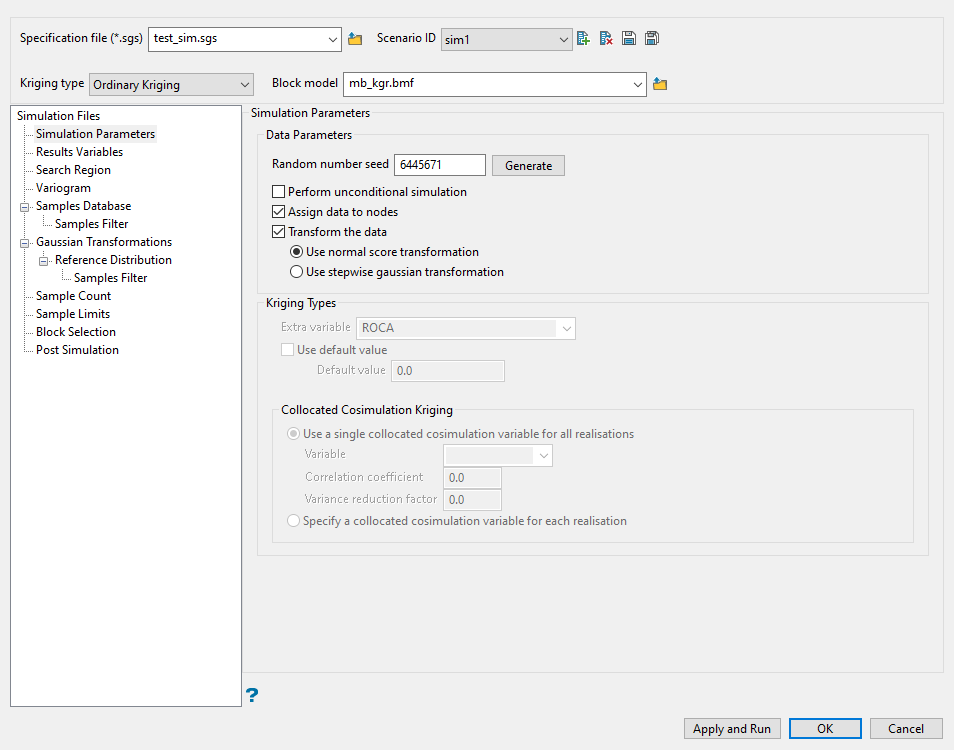
Follow these steps:
-
Enter a name for the Specification file, or select it from the drop-down list. The drop-down list displays all files found in the current working directory that have the (.bef) extension. Click the Browse icon
 to select a file from another location.
to select a file from another location.
-
Select a Scenario ID. To create a new ID, click the New icon as shown below, and provide a unique name for the current panel settings. Up to nine separate IDs can be created for each BEF file.
-
Select the Kriging type to use when establishing the conditional distribution parameters.
The following methods are available:
-
Simple kriging
-
Ordinary kriging
-
Locally Varying Mean (LVM) kriging
-
Kriging with an external drift
-
Collocated cokriging
-
-
Select the Block model from the drop-down list. Click the Browse icon
to select a file from another location. -
Enter the Random number seed number. Click the Generate button if you want Vulcan to produce the seed number. The random numbers are used for the random path and for drawing from the conditional distribution.
-
Select Perform unconditional simulation to perform a simulation without using data. If this check box is checked, then all sections related to sample data will be unavailable.
-
Selecting Assign data to nodes will cause sample locations to be slightly modified as they will be considered to be at the location of the closest node within the block model. This allows for faster simulation results, however, some samples could be lost as when more than one sample is contained in a block, only the closest is assigned and the other is discarded for simulation. Discarded samples are still used to build the global distribution and Gaussian transformation if required.
-
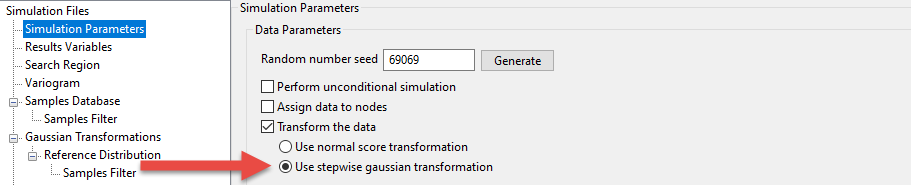
Select Transform the data if the data is provided in grade units. The sample data in grade units will be transformed to a Gaussian distribution by one of the available Gaussian transformations, that is, Normal Scores or Stepwise conditional. If this check box is checked, then you will need to select the transformation to use.
-
Specify the Extra variable needed for LVM kriging or Kriging with an external drift.
Note: This option is not available when using Simple kriging, Ordinary kriging, or Collocated cokriging.
-
Select Default value to set the default value here instead of using the default in the block model.
-
Select Use a single collocated cosimulation variable for all realisations if you only want to use one variable for all realisations.
-
If you use this option, select the block model Variable from the drop-down list.
-
Enter the Correlation coefficient value that will be used to derive the secondary variable and cross variogram when using Collocated cokriging.
-
Enter the Variance reduction factor value that will be used to modify the kriging variance after collocated cokriging.
Example: A factor of
1will result in no change, while a factor of0.5will result in a 50% variance reduction.
-
-
Select Specify a collocated cosimulation variable for each realisation if you want to choose the variables that will be used on the Results Variables pane.
Results Variables
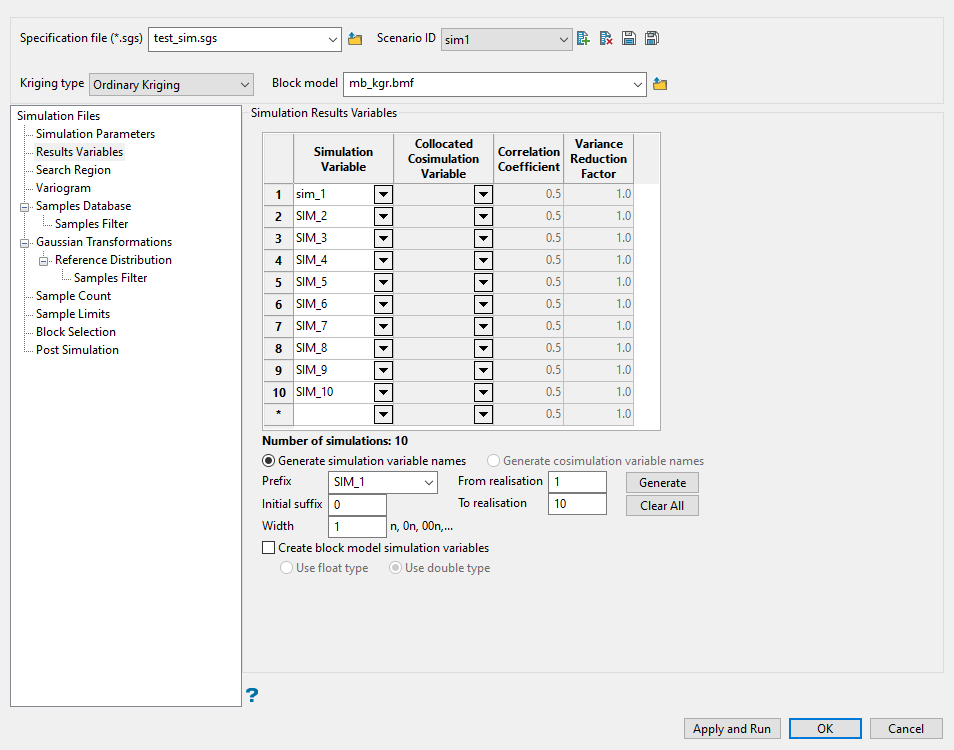
Use this pane to select the variable that will be used to store each one of the realisations. In addition, an automatic tool can be used to create the necessary variables.
Follow these steps:
-
Enter the Prefix for the variable name. You can use one from the drop-down list or enter your own.
-
Enter the starting number in the sequence in the Initial suffix field.
-
Enter the minimum number of characters that can be used to represent a number in the Width field.
Example: A prefix of
simwith an initial suffix of1and a width of3would result insim001as the first simulation field. -
Specify an initial and final realisation in the From realisation and To realization fields. These values are only used to calculate the number of realisations.
-
Use the Generate button to populate the Simulation Variable list. This is a list of variable names that will hold the results of the individual realisation runs.
Click the Clear All button to remove all entries and delete the current list.
Note: Clearing the list does not delete existing variables from the block model.
-
Select Create block model simulation variables if you want to create the variables when saving the specification file. If the variables already exist within the nominated block model, then a warning message will be displayed when the specification file will be saved.
-
Indicate the type of variable to create by selecting either Float or Double.
Float (Real * 4)
This is a real number taking up 4 bytes. It is generally used for single precision numerical data codes such as grades and densities - up to seven significant figures.
Double (Real * 8)
This requires two consecutive storage units (taking up 8 bytes) providing greater precision than real number types and is used for numbers up to 14 significant figures.
-
Select the Colocated Cosimulation Variable from the table if you are using the option Specify a collocated cosimulation variable for each realisation from the Simulation Parameters pane.
Also, make any needed adjustments to the Correlation coefficient and Variance reduction factor.
Search Region
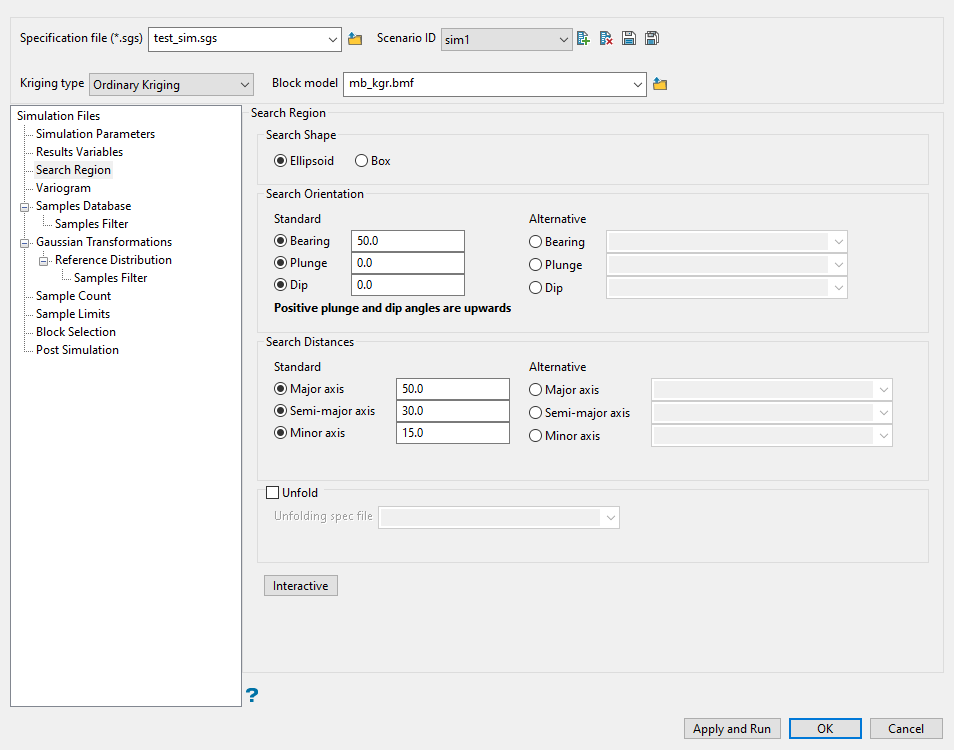
Use this pane to define the search distances and search orientation.
Follow these steps:
-
Select the shape of your search region.
Use search ellipsoid - Select this option to limit the search distance to an ellipsoid.
Use search box - Select this option to limit the search distance to a box instead of an ellipsoid.
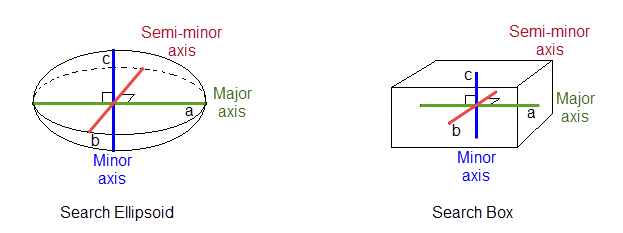
Note: The volume of a box with sides 2a, 2b and 2c is about twice the volume of an ellipsoid with radii a, b and c. Therefore, when using the box search you collect about twice as many sample points. This causes an estimation using a box search to take from two to eight times as much time as an estimation with a search ellipsoid.
-
Enter the angles for the Bearing, Plunge, and Dip.
Note: You can enter the angles directly or select block model variables that contain the angles by choosing the Alternative options.
 Search Orientation
Search Orientation
The Bearing, Plunge and Dip values are angles, in degrees, that specify the orientation of the search ellipsoid and orientation of variogram structures. Care must be taken with these parameters as there are several common misunderstandings about the meaning of these parameters.
To understand these parameters, imagine an ore body with a primary axis. To find the bearing of the ore body, project the ore body axis straight up onto the surface plane and call this line the bearing line. The bearing is the angle clockwise from north to the bearing line.
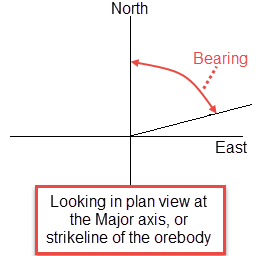
Figure 1 : Bearing
Plunge is the angle between the horizontal plane and the ore body axis. Note that the plunge should be negative for a downward pointing ore body.
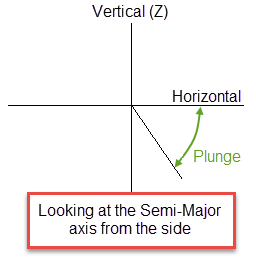
Figure 2 : Plunge
To find the dip of an ore body, imagine the ore body is located in a plane. First rotate around the Z axis by the bearing so that the ore body is pointing north. Then rotate around the east-west axis by the plunge so that the ore body is level with the ground. At this point the ore body is parallel to the north-south axis. The dip is the angle of rotation to bring the plane into the horizontal plane. Looking north, if the plane must be rotated clockwise around the north-south axis, then the dip is positive (other software packages may use the opposite convention).
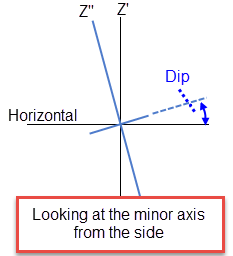
Figure 3 : Dip
Note: The terms bearing, plunge and dip have been used by various authors with various meanings. In this panel, as well as kriging and variography, they do not refer to true geological bearing, plunge and dip. The terms X', Y' and Z' axis are used to denote the rotated axes as opposed to X, Y and Z which denote the axes in their default orientation.
-
Enter the dimensions of the search region.
Search Distances
The search box has sides with length twice the numbers given. The major axis radius is the search distance along the axis of the ore body. The semi-major radius is the search distance in the ore body plane perpendicular to the ore body axis. The minor axis radius is the search distance perpendicular to the ore body plane.
Note: Use the Display Ellipsoid option to verify that you are using the proper orientation angles. Display the search ellipsoids over your sample data to verify the correct orientation of the ellipsoid.
The search radii are true radii. If you set your major search radius to '100', then the ellipsoid has a total length of 200. The following diagram shows the relationship between the axes with the ellipse in the default orientation (bearing 90°, plunge and dip 0.00°).
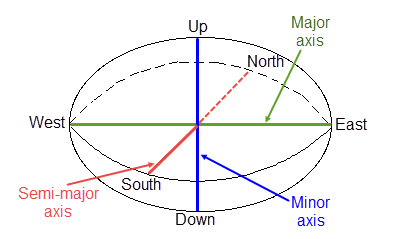
Figure 4 : Relationship between Radii
-
Select Unfold to use a tetrahedral model. This is applicable only for folded or faulted block models for which a tetrahedral model has been created.
-
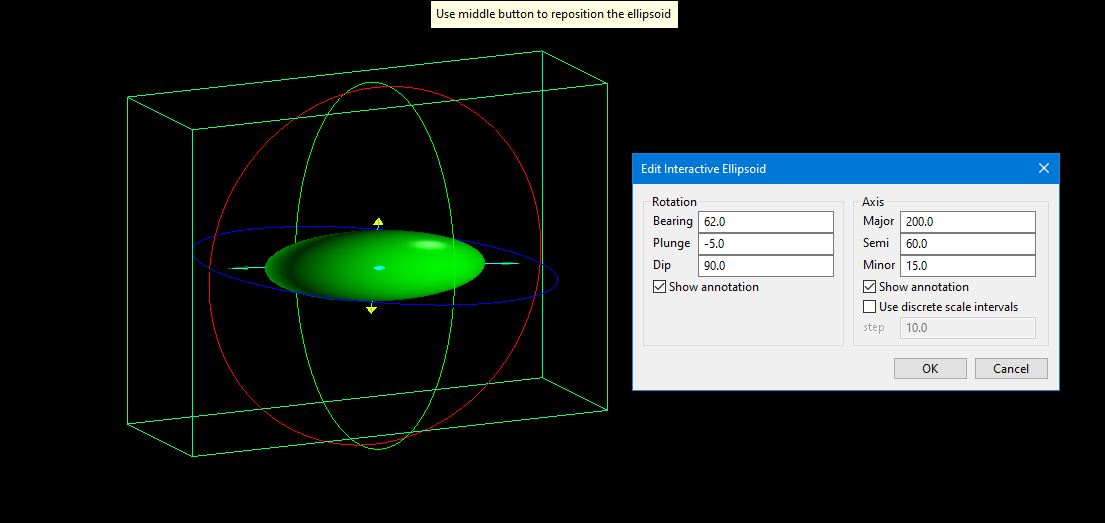
Click the Interactive button to adjust the search distances and orientation visually.
-
Set the origin by selecting a location on the screen. This point is an arbitrary point used to define the starting location for measuring the distance and orientation.
-
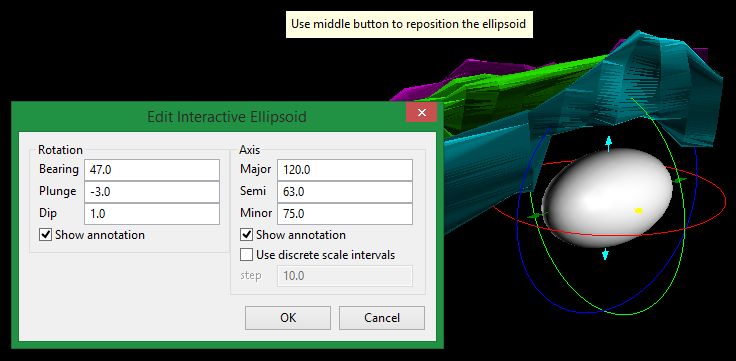
Set the parameters for rotation by adjusting the Bearing, Plunge, and Dip. Set the parameters for the distances by adjusting the Major, Semi, and Minor settings. You can do this by entering the numbers manually, or by clicking and dragging the arrows and rings on the screen.
-
Select Show annotations to toggle the display for showing the arrows.
-
Select Use discrete scale intervals to limit increasing or decreasing the distances by the Step size you enter.
-
Click OK to return to the main panel.
-
Variogram
Follow these steps:
-
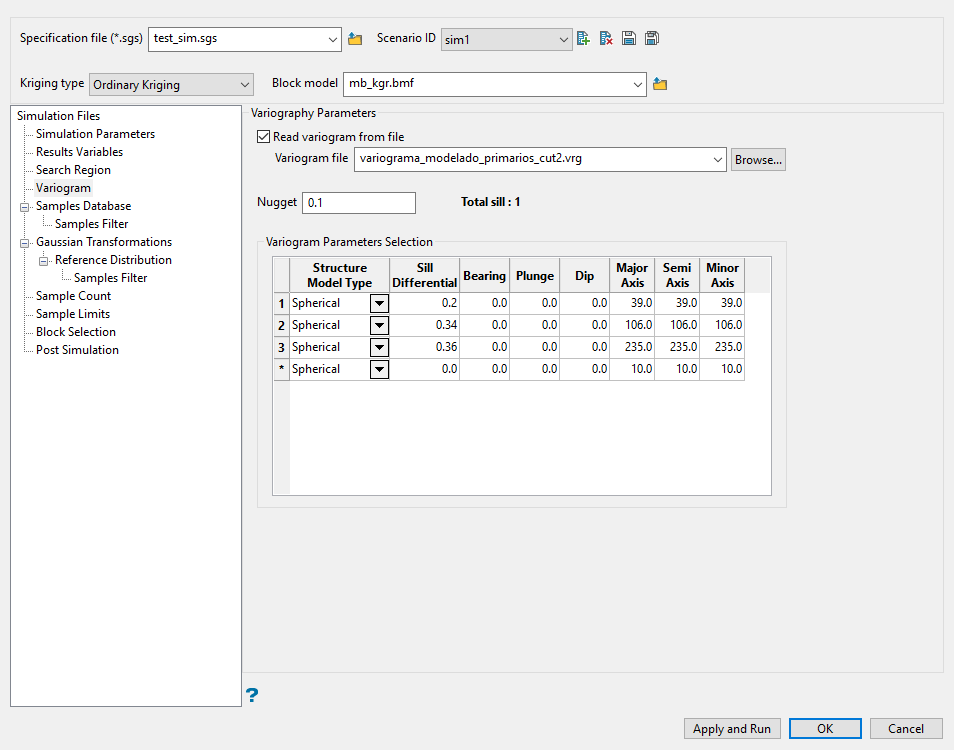
Select Read variogram from a file to use an existing variogram model. Use the drop-down list to select the model. Variogram models are stored in (.vrg) files.
-
Enter the nugget.
-
Select the type of model from the drop-down list labelled Structure Model Type.
The variogram model type can be one of the following:
Spherical
This type is the most commonly used for ore deposits. They exhibit linear behaviour at and near the origin then rise rapidly and gradually curve off.
Exponential
This type is associated with an infinite range of influence.
The sill is reached at the specified range parameter. In release 3.2 and earlier, users were required to enter a range parameter of one-third the practical sill range. To use this model, enter the practical distance of the sill as a range parameter. For backward compatibility, see the Exponential Model 3.
Gaussian
This type exhibits parabolic behaviour at the origin and, like the spherical model, rises rapidly. The Gaussian type reaches its sill smoothly, which is different from the spherical model, which reaches the sill with a definite break. The Gaussian model is rarely used in mineral deposits of any kind. It is used most often for values that exhibit high continuity.
In release 3.2 and earlier, users were required to enter a sill range of 3 times the actual sill range. To use this model, enter the effective range of the sill. For backward compatibility, see the Gaussian model 3.
Linear
This type is a straight line with a slope angle defining the degree of continuity.
De-Wijsian
This type is a representation of a linear semi-variogram versus its logarithmic distance.
Power
This type is computed as M - d**p where M = the maximum correlation defined as 1000.0, d = distance from the origin, p = model power. For this model type only the power p is the major axis radius. Adjust the size of the ellipsoid so that the major axis is the desired power. The size of the ellipsoid for this model does not change the calculation of the variogram.
Exponential Model 3
This is an un-normalised exponential model for compatibility with release 3.2 and earlier. This variogram will have the practical sill at three times the distance entered as range parameter.
Periodic
This is a sine wave with one complete period over the effective range. This model is not commonly used because it can cause samples at greater distances to have higher correlation.
Gaussian Model 3
This is an un-normalised Gaussian model for compatibility with release 3.2 and earlier. The input radius must be the effective radius multiplied by 3.
Dampened Hole Effect
Dampening is achieved by multiplying the covariance function by an exponential covariance, that acts as a dampening function.
-
Enter the Sill Differential. This represents the difference between the value of the variogram where it levels off and the nugget. For example, if you have a total sill of 1.0, and a nugget of 0.15, you want your sill differential to be 0.85 = (1.0 - 0.15).
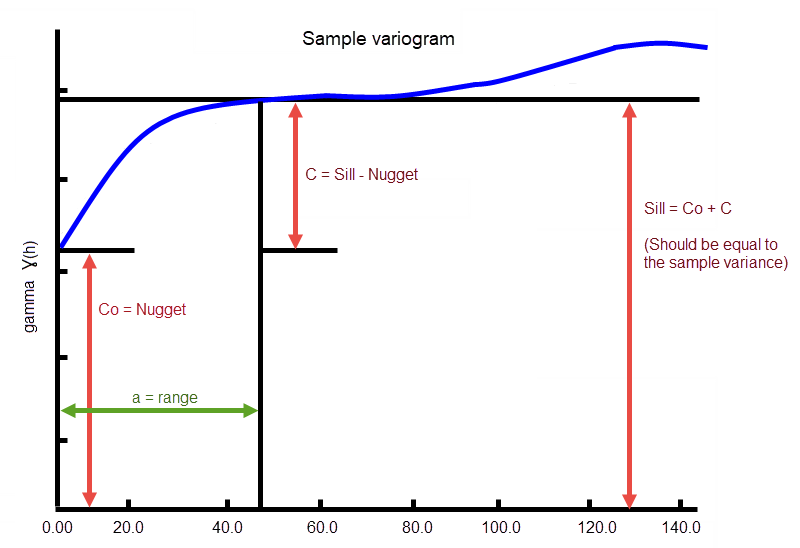
In the diagram, C0 is the nugget, and C is the sill differential.
-
Enter the Bearing (Rotation about the Z axis), Plunge (rotation about the Y axis), and Dip (rotation about the X axis) of the variogram.
-
Enter the radii of the Major, Semi, and Minor axes of the variogram.
Samples Database
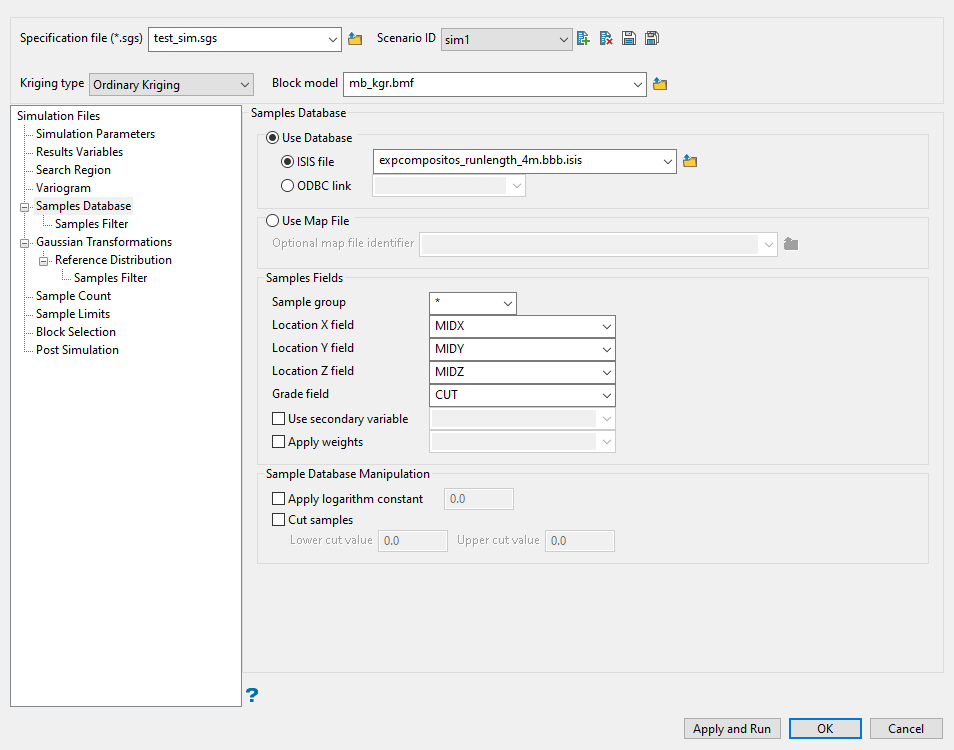
Use this pane to define the source of your samples. You can use an Isis database or a map file.
Follow these steps:
-
Select either a database or map file as your sample source.
-
To select a database, enable the option ISIS file, then select the file from the drop-down list. Click folder icon to select a file from another location.
You can also select an ODBC link for database files found on site servers.
-
To select a map file, enable the option labelled Use Map File, then select the file from the drop-down list. Click the Browse button to select a file from another location.
-
-
Map the correct fields by filling out the Samples Fields information.
-
Sample group - Enter the name of the groups (database keys) to be loaded in the field. Wildcards (* multi-character wildcard and % single character wildcard) may be used to select multiple groups. Multiple groups only apply to Isis databases (ASCII map files consist of one group).
-
Select the names of the fields containing the X, Y, and Z coordinates in the Location fields.
-
Select the name for the variable containing the Grade values.
-
-
Select one or both of the Sample database manipulation options to apply to your data. This is not required.
-
Apply logarithm - Select this option to apply the base logarithm function to all sample values.
Note: All original sample values must be positive for the logarithm to be defined. The specified logarithm constant is added to the calculated logarithm.
-
Cut grade samples - Select this option to apply cut-offs to the grades used in the estimation. Specify a lower grade cut value (grades lower than this value are set to this value) and an upper grade cut value (grades above this value are set to this value).
-
Samples Filter
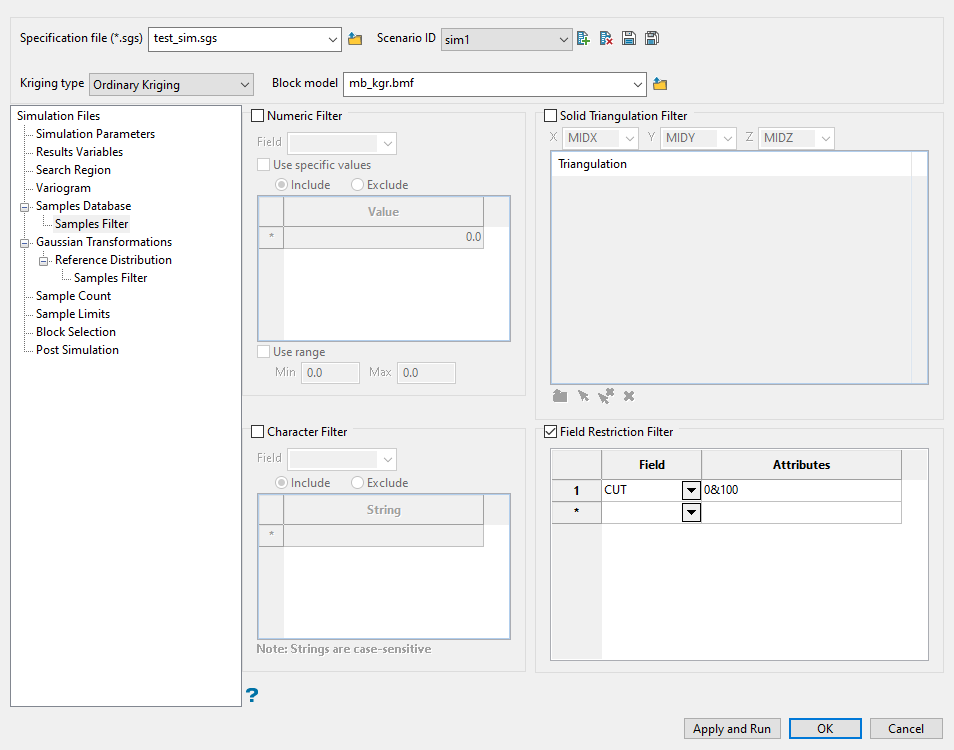
Use this pane to include any restrictions to your data by using the four specialised filters.
Follow these steps:
-
Include any restrictions to your data by using the four specialised filters.
Select using Numeric tag
Use this filter to limit a numeric variable by only using specific values, ignoring specific values, or setting a range of values that can be used.
Follow these steps:
-
Enable this pane by selecting Sample Selection Using a Numeric tag.
-
Select the numeric field from the drop-down list.
-
Select Use specific numeric values to limit the values to only those listed in the table.
-
Select Ignore certain numeric values to create a list of values that will be ignored.
-
Select Use a numeric range to use all values found between a minimum and maximum threshold.
Note: You can use more than one filter. However, keep in mind that all conditions must be met for a value to be used.
Select using Character tag
Use this filter to limit a character variable by only using specific values or ignoring specific values.
Follow these steps:
-
Enable this pane by selecting Sample Selection Using a Character tag.
-
Select the Character field from the drop-down list.
-
Select Use specific character values to limit the values to only those listed in the table.
-
Select Ignore certain character values to create a list of values that will be ignored.
Note: You can use more than one filter. However, keep in mind that all conditions must be met for a value to be used.
Select using Solid triangulations
Use this filter to limit the samples by one or more triangulations.
Follow these steps:
-
Enable this pane by selecting Select using solid triangulations.
-
Add triangulations to the list by clicking the Browse or Screen Pick button.
Clicking Browse will cause an Explorer panel to display.
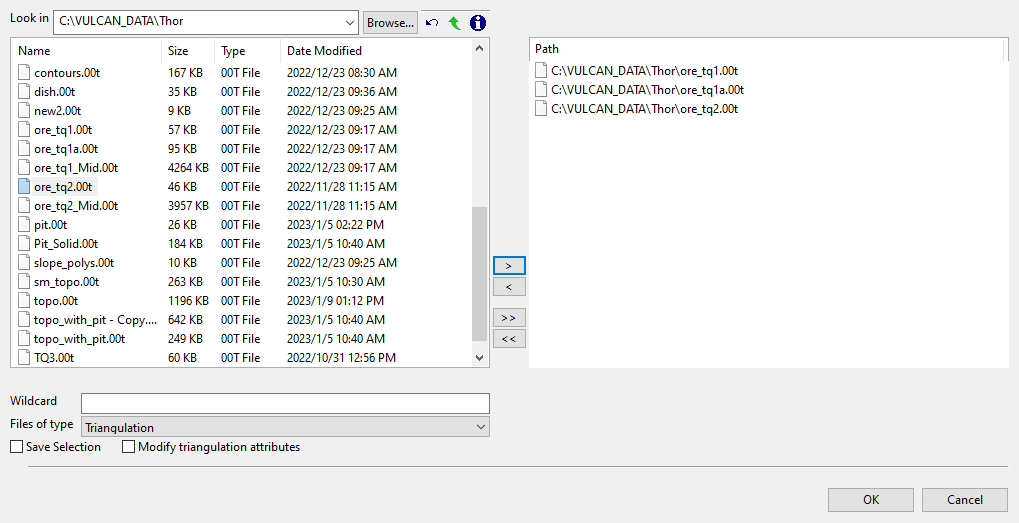
Select Triangulation(s) panel
-
Select the desired triangulation file(s) from the file list, which shows all available files in the current working directory. You can select files from a different location by clicking Browse..., or use the
 buttons to go to the last folder visited, go up one level, or change the way details are viewed in the panel, respectively.
buttons to go to the last folder visited, go up one level, or change the way details are viewed in the panel, respectively.To highlight multiple list items at once, use the left mouse option in combination with the
Shiftkey (this is for items that are adjacent in the list; for non-adjacent items, use theCtrlkey and the left mouse option).TipTo filter file names using wildcard characters, type in a pattern in the Wildcard field using
*> for a multi-character and?> for a single-character wildcard.If you would like to use a previously created selection file (.sel) containing a list of desired triangulation files to load, choose Selection Files (*.sel) from the Files of type drop-down list.
-
Move the items to the selection list on the right side of the panel.
- Click the
 button to move the highlighted items to the selection list on the right.
button to move the highlighted items to the selection list on the right. - Click the
 button to remove the highlighted items from the selection list on the right.
button to remove the highlighted items from the selection list on the right. - Click the
 button to move all items to the selection list on the right.
button to move all items to the selection list on the right. - Click the
 button to remove all items from the selection list on the right.
button to remove all items from the selection list on the right.
- Click the
-
Select the Save Selection checkbox if you want to save the selection list (the right side of the panel), to a nominated selection file (
.sel). Once this panel has been completed, a panel displays to save the selection file. Choose a selection file from the File Explorer to store the triangulation selection list to and click Save. To create a new file, enter the file name.
-
Click OK to load the list of selected triangulations. Alternatively, click Cancel to close the panel without loading the selected triangulations.
-
-
Removing triangulations from the list by clicking the Clear Selected or Clear All button.
Select using Field restrictions
Use this filter to limit the samples to those with fields that match certain selection criteria.
Follow these steps:
-
Enable this pane by selecting Select selection using field restriction.
-
Select the field from the drop-down list in the Field column.
-
Enter the conditions that must be met in the Attributes column.
Include spaces only if spaces are included in the desired field values.
When entering a range, always enter the smallest number specified before the largest number.
Example:
-792&-720since-792is smaller than-720. This range is evaluated as-792.0 ≤ VALUE < -720.0.
Note: You can enter more than one condition. However, keep in mind that all conditions must be met for a value to be used.
-
Gaussian Transformations
![]()
The options that are displayed on this pane will differ depending on the method to transform the data you selected on the Simulation Parameters pane: Normal score transformation or Stepwise Gaussian transformation.
Follow these steps for Normal Score transformation:
![]()
-
Enter the Minimum value to be used in the distribution. This value should be less than the smallest cut-off.
-
Enter the Maximum value to be used in the distribution.
-
Select a model for each section of tail attribute using the drop-down lists.
Power model for left tail - This describes the shape of a curve from the Minimum data value to the lowest cut-off. If this value is less than 1, then the distribution is skewed towards the minimum data value. If it is greater than 1, then the distribution is skewed towards the lowest cut-off. If it is equal to 1, then the distribution is flat from the minimum data value to the lowest cut-off.
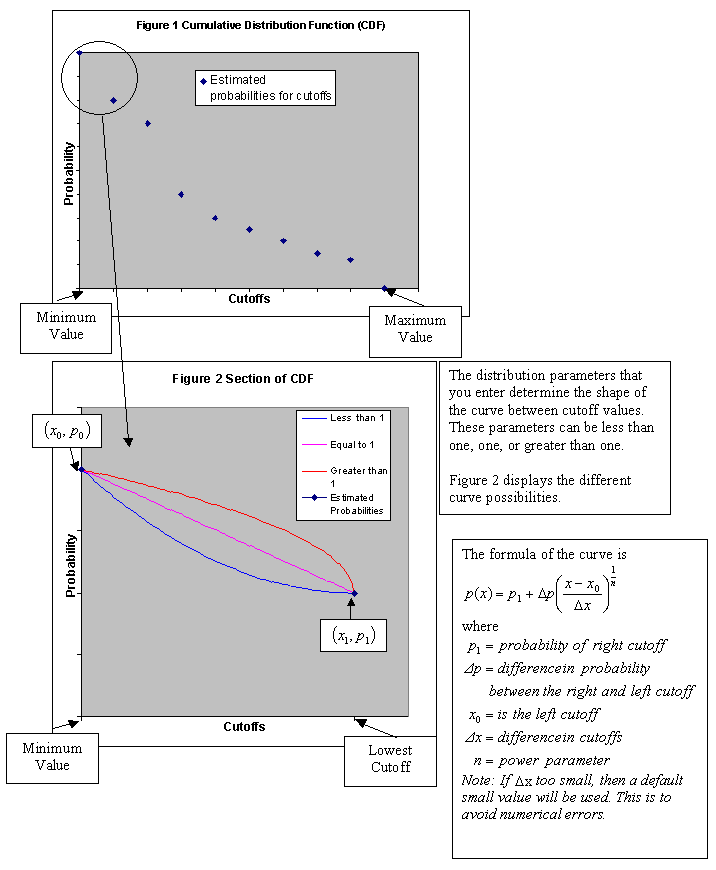
Power model for right tail - This option gives a distribution with a maximum data value. The maximum data value should be larger than the highest cut-off. The power for the right tail curve controls the shape of the distribution above the highest cut-off. If the power is less than 1, then the distribution is skewed towards the highest cut-off. If the power is greater than 1, then the distribution is skewed towards the maximum data value.
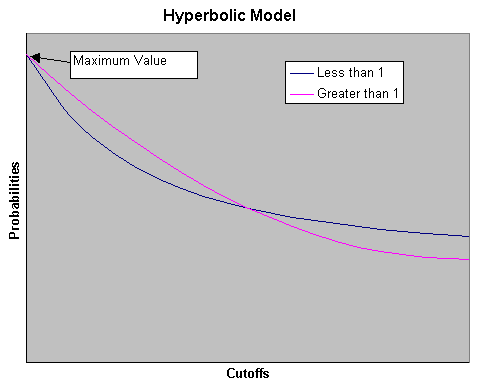
Hyperbolic model for right tail - This option gives a distribution with no maximum. If the power is greater than 1, then the distribution contains more values closer to the highest cut-off and less higher values. Whereas if the power is less than 1, then the distribution contains less values closer to the highest cut-off, but more higher values. The hyperbolic model right tail option always allows for the possibility of arbitrarily large simulated values.
-
Select Save transformation table to save the values used in the transformation to a file. Enter a name for the file in the field provided. The new file will be stored in your current working directory with the extension (<filename>.ns.tfn).
-
Select Normal score back transform if you want the results to be back transformed from Gaussian values to the units of the attributes that are being simulated. If this check box is not checked, then the results will remain in Gaussian units.
Follow these steps for Stepwise Gaussian transformation:
![]()
-
Enter the Number of classes in which to divide the primary variable. This must be selected according to the number of available data pairs.
-
Enter the Number of quantiles to use. The transformation lookup table will not store all the information for the transformation of each class, instead a number of quantiles are used. Interpolation will be used for values between selected quantiles.
-
Enter the Minimum number of data per class. If there is less than this number of pairs in a given class, then a dynamic expansion technique is used in order to get more pairs. The class in the primary variables will be expanded until the minimum number of samples is reached.
-
Select Conditioning variable if you want to use conditioning data. The drop-down list displays all of the block model variables contained in the chosen block model.
Tip: As more conditioning data are used the estimate will be improved and the kriging variance is reduced. The reduced variance will limit the possibility of drawing implausible values.
-
Select Save transformation table to save the values used in the transformation to a file. Enter a name for the file in the field provided. The new file will be stored in your current working directory with the extension (<filename>.ns.tfn).
Reference Distribution
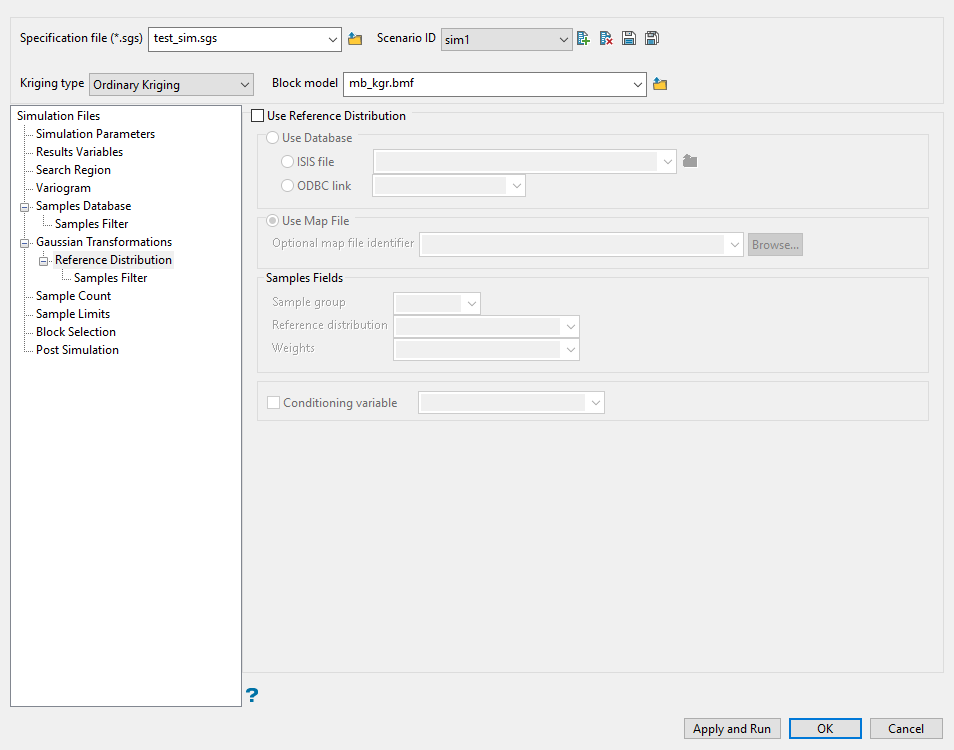
Use this pane to use a different dataset to create the transformation lookup table to use with the block model data. In this case all the transformation conversion is defined using the reference database, but the data that gets transformed is defined through the Samples Database section of the interface.
Follow these steps:
-
Select either a database or map file as your sample source.
-
To select a database, enable the option ISIS file, then select the file from the drop-down list. Click folder icon to select a file from another location.
You can also select an ODBC link for database files found on site servers.
-
To select a map file, enable the option labelled Use Map File, then select the file from the drop-down list. Click the Browse button to select a file from another location.
-
-
Enter the name of the Sample Group to be loaded. Wildcards (* multi-character wildcard and % single character wildcard) may be used to select multiple groups. Multiple groups only apply to Isis databases (ASCII mapfiles consist of one group).
-
Select the grade variable that will be used to construct the transformation lookup table in the field labelled Reference distribution.
-
Select the database field containing the Weights that can be used to build the reference grade distribution. Sample values are not changed by the weighting, only its relative importance in the distribution is adjusted. Leave this field blank if you do not want to apply any weighting.
-
Select Conditioning variable to use a conditioning data. The drop-down list displays all of the block model variables contained in the chosen block model.
Tip: As more conditioning data are used the estimate will be improved and the kriging variance is reduced. The reduced variance will limit the possibility of drawing implausible values.
NoteTo enable this option you must select the option Use stepwise gaussian transformation on the Simulation Parameters pane, and the option Conditional variable on the Gaussian Transformations pane.

Sample Count
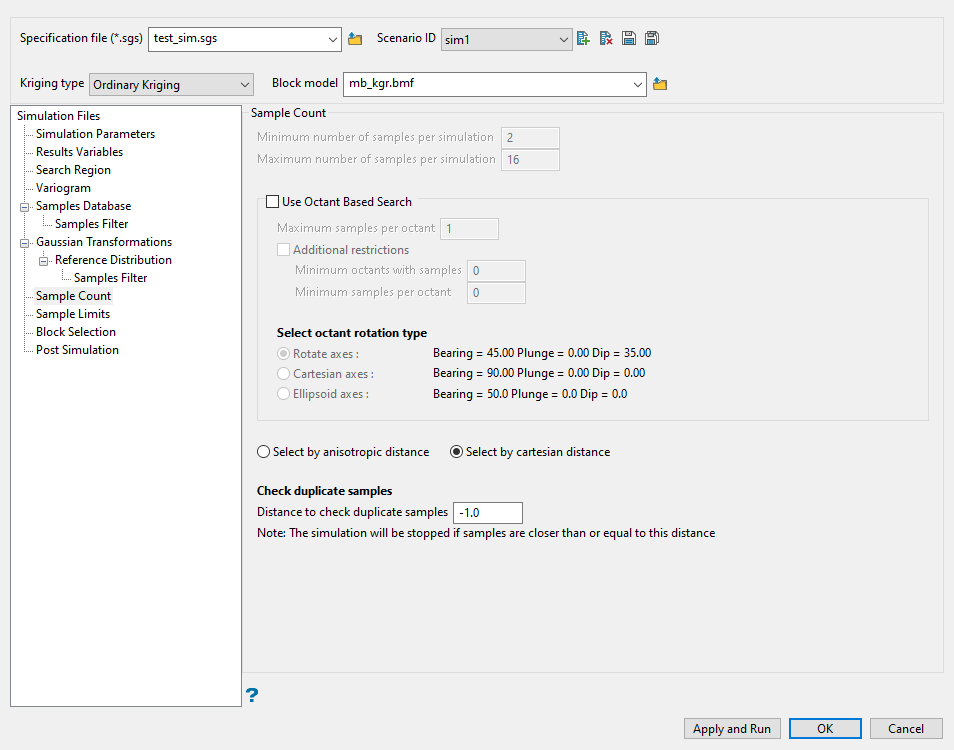
Use this pane to determine how many samples you want to use during the calculation of each block.
Follow these steps:
-
Enter the Minimum number of samples per estimate that have to be found to generate an estimate. Blocks with less than this number of samples within the search ellipsoid or box are assigned the default grade value.
-
Enter the Maximum number of samples per estimate to be used in any grade estimation. For example, the estimation program may find 30 samples near a block centre. If you had specified a maximum of 10 samples, then only the 10 samples closest to the block centre are used. The distance to the block centre is calculated by an anisotropic distance based on the search radii. Up to 999 samples per estimate are allowed.
-
Select Use Octant Based Search if you wish to have more control over the number of samples taken from each octant.
Note: An octant search is a declustering tool used to reduce imbalance problems associated with samples lying in different directions. If there are more samples in one direction than the another, then this option limits the bias.
-
Enter the Maximum samples per octant to be used in the estimation. Samples closest to the block centre are used first.
Note: The maximum number of samples per estimate always applies, regardless of the maximum samples per octant value.
-
Select Additional restrictions to apply additional restrictions to the number of samples for octants. These restrictions comprise of minimum octants with samples and minimum samples per octant.
The minimum octants with samples enables you to specify the number of octants that must contain samples for an estimate to be generated. The minimum samples per octant enables you to specify the number of samples per octant that needs to be found to generate an estimate. These two restrictions work together. An octant is considered "filled" if it contains at least the minimum number of samples per octant. The minimum number of octants with samples requires that at least that number of octants be filled.
If you set the minimum number of samples per octant to 2, the minimum number of octants to 3 and have the following number of samples per octant, there are two filled octants. As this is less than the minimum number of octants with samples, the default value is assigned to this block.
Octant Number Number of samples per octant Filled / Not Filled 0 1 Not filled 1 3 Filled 2 2 Filled 3 1 Not filled 4 1 Not filled 5 1 Not filled 6 1 Not filled 7 0 Not filled
-
Select an Octant rotation type.
Rotate axes This consists of three planes perpendicular to axes that have been rotated 45° about the Z axis and 35° about the X' (X axis after rotation about the Z axis), this produces a set of planes in which the first has a bearing of 135°, the second has a bearing of 45° and is at angle of -55° to the horizontal and the third also has a bearing of 45°, but is at an angle of 35° to the horizontal. (See the diagram below.) Cartesian axes This consists of three planes perpendicular to the conventional Cartesian axes X, Y, and Z (or East, North, and elevation) axes. Ellipsoid axes This consists of three planes that are perpendicular to the major, semi-major, and minor axes of the search ellipsoid. 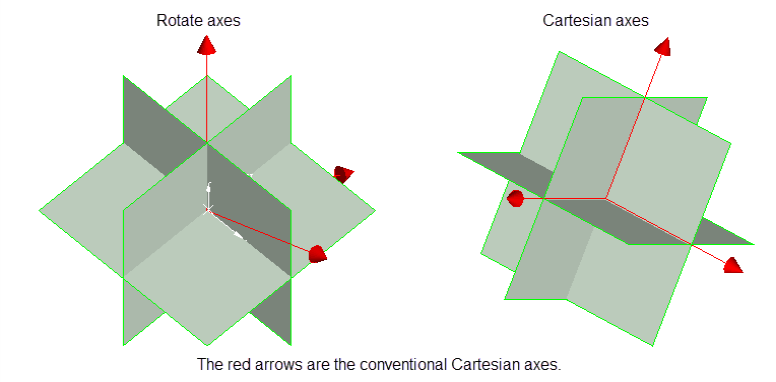
-
Select the method by which the samples will be measured by choosing either Select by anisotropic distance or Select by Cartesian distance. The samples are sorted by distance (either anisotropic or Cartesian) prior to the samples being limited. This ensures that the closest samples are kept.
-
To prevent the same sample from being used more than once, enter the distance to use in Distance to check duplicate samples. Samples less than or equal to the specified distance value are considered to be duplicates, resulting in the entire grade estimation process being stopped. You can disable this feature by specifying a distance value of
'-1'.
Sample Limits
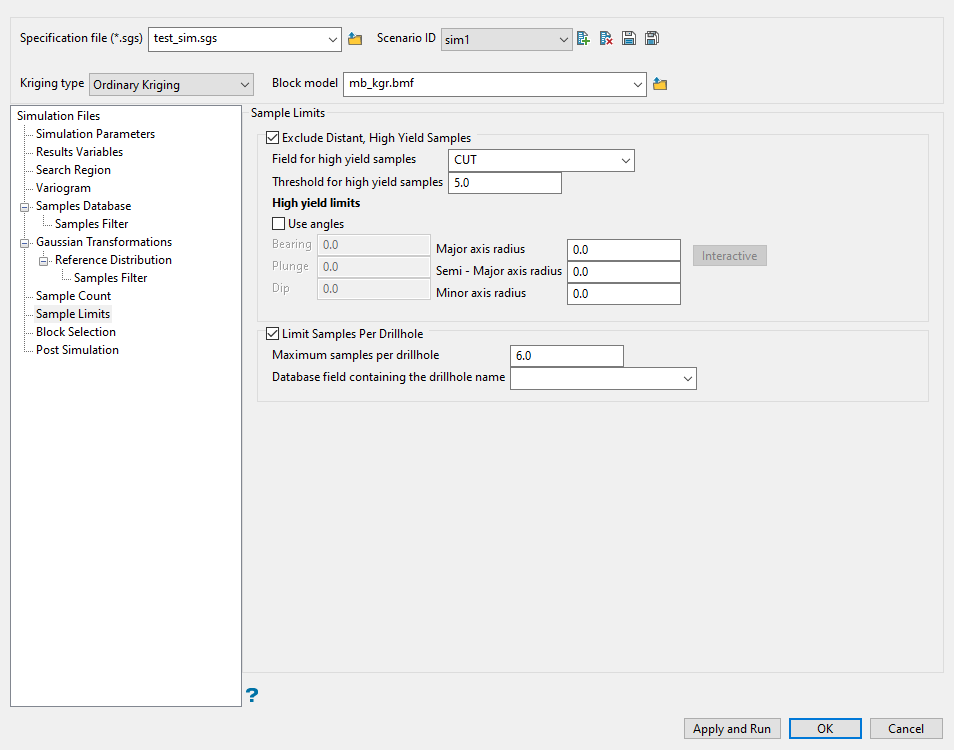
Use this pane to limit samples. The high yield exclusion ellipsoid specified here has its own major, semi-major and minor axes distance ranges, but have the same orientation as the ellipsoid defined through the Search Region section. When selecting the samples, any sample within the high yield exclusion ellipse can be chosen whether it is greater than or less than the threshold. However, between the smaller high yield exclusion ellipse and the normal Search Region ellipse, only samples that are less than the threshold can be chosen. This is commonly used to avoid estimation from high gold nugget values to distant blocks.
Follow these steps:
-
Select Exclude distant, high yield samples to ignore sample values at or above the specified threshold and outside the specified ellipsoid.
-
Specify which field to use from the Field for high yield limit list. It is usually the same as the input grade field. However, other fields can be used to achieve special sample limits.
Example: You can specify a flag field in which '0' represents an ordinary sample and '1' represents a special sample. A threshold of '0.5' would then limit the flagged samples to a smaller radius.
-
Enter a grade limit in the field Threshold for high yield samples.
-
Select Use angles if you wish to apply custom dimensions to your search ellipsoid instead of using just the sample value when determining if it will be used or not.
-
Enter the angles for the Bearing, Plunge, and Dip for the high yield exclusion ellipsoid.
-
Enter the distances for the Major, Semi-Major, and Minor axes radii for the high yield exclusion ellipsoid.
Interactive Button
Click the Interactive button to display an ellipsoid that can be edited by manipulating it with the mouse or entering the rotation and axis parameters directly.
-
-
Select Limit Samples Per Drillhole if you want to limit the number of samples that can be used from each drillhole.
Note: The estimation uses the samples closest to the centre of the block.
-
Enter the Maximum number of samples per drillhole.
-
Specify the Database field containing the drillhole name. The default is DHID.
-
Block Selection
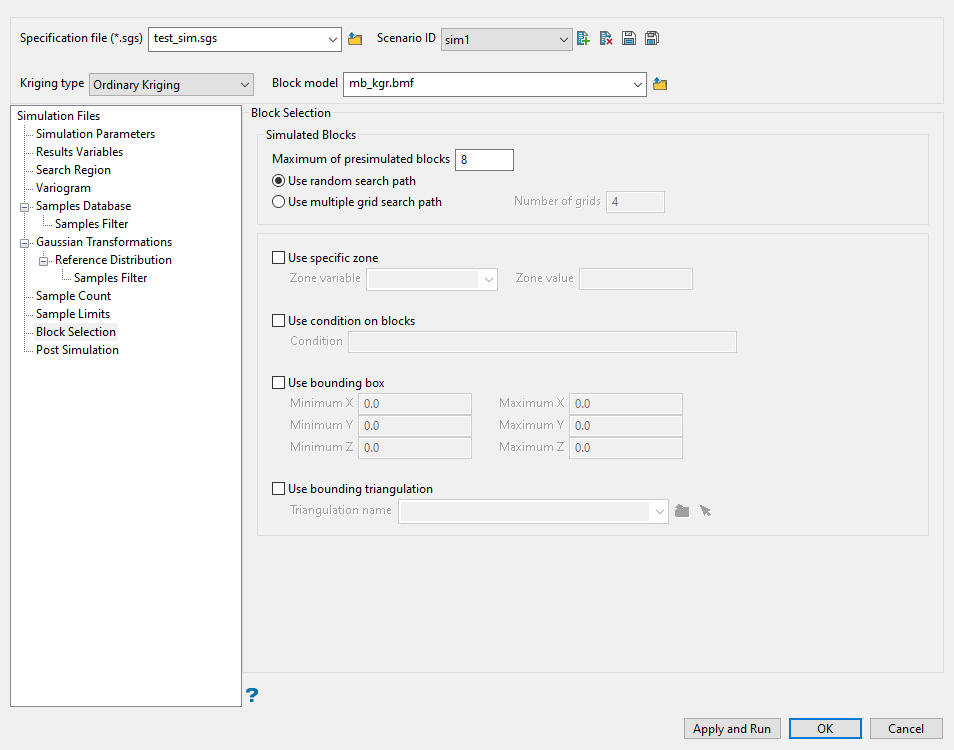
Use this panel to set up various block selection options.
Follow these steps:
-
Enter the maximum number of previously simulated grid nodes that will be used together with sample information in order to simulate block model nodes in the Maximum of presimulated blocks field. If the samples were not assigned to nodes through the Simulation parameters section, then the maximum number of samples will be controlled by the parameters specified through the Search region section.
If the samples were assigned to nodes, then the parameter specified at the sample counts are ignored and the maximum number of presimulated block nodes will apply to samples (already assigned to nodes) and nodes populated by simulation.
-
Select Use random search path to simulate the nodes in a random order.
-
Select Use multiple search grid path to perform a grid ordering as a first step before going into the random path. The grid refinement begins by simulating the nodes at a coarse regular grid spacing. The coarse grid spacing can then be further refined to half of the previous spacing.
-
A maximum number of 4 consecutive grid refinements can be requested in the Number of grids field. After the regularly spaced nodes are simulated the remaining nodes are selected using a random path.
-
Select any of the options to limit the blocks used.
Select this checkbox to limit the estimation to those blocks where a specified variable equals a certain value. Both the variable and the value are forced to be lowercase.
Select this checkbox if you only want to apply a condition to the blocks to be estimated. A single condition can contain up to 132 alphanumeric characters. For a condition to contain more than 132 alphanumeric characters, you will need to manually edit the (.bef) file. Refer to Appendix B of the Vulcan Core documentation for a list of available operators/functions.
Select this checkbox to restrict the estimation to those blocks whose centroids lie within a specified range of co-ordinates. Enter the minimum and maximum co-ordinates (in the X,Y and Z directions). These co-ordinates are offsets from the origin of the block model (that is, block model co-ordinates).
Select this checkbox to limit the estimation to those blocks that lie within a specific solid triangulation. The triangulation name can either be manually entered or selected from the drop-down list. Click Browse to select a file from another location. You can also select loaded triangulations from the screen by clicking the Pick Screen option.
Post Simulation
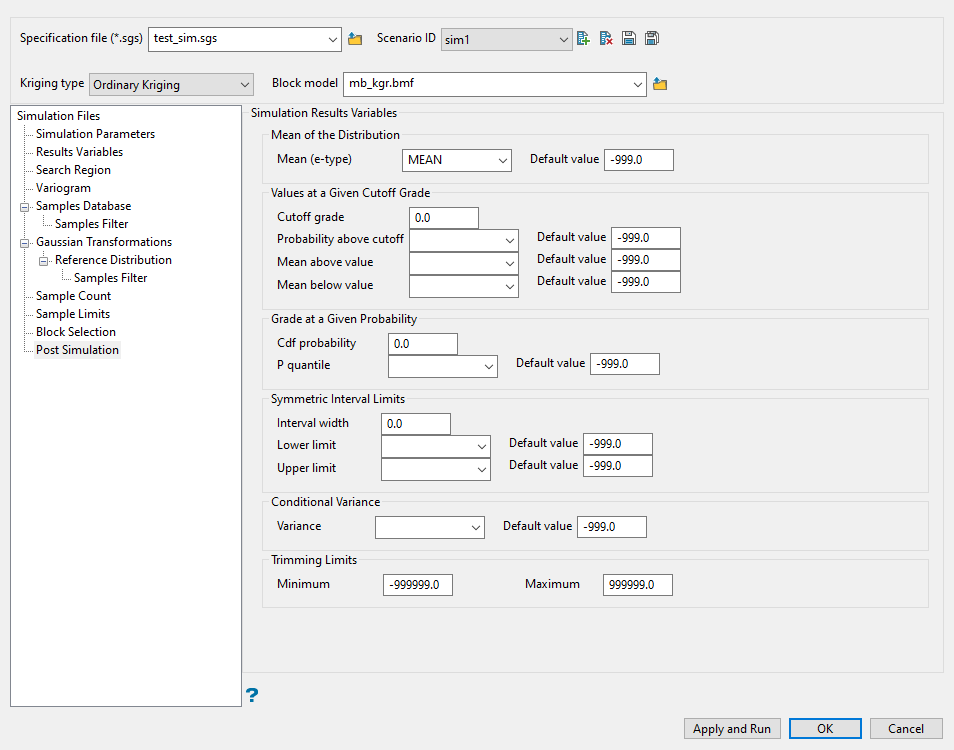
Use this pane to define the variables that will hold the results of the simulation.
Follow these steps:
-
Specify the block model variable where the Mean (the average of all realisations) for each block will be stored. Provide a default value in case no realization fall within the minimum/maximum trimming limits. If a variable is not supplied, the calculation of the conditional mean from the simulation realisations will be ignored.
-
Use the Value at a given cutoff section to read the conditional distribution based on a given cutoff grade. The cutoff grade will be used to divide the distribution of realisations into a part above the cutoff and another part below the cutoff.
-
Enter a Cutoff grade to use for the analysis. The same cutoff grade will be used for all selected blocks.
-
Specify the Probability above cutoff. This is the block model variable where the probability to be less than or equal to the cutoff will be stored. If a variable is not supplied, then this calculation will be ignored. Provide a default value in case no realisations fall within the minimum/maximum trimming limits.
-
Specify the Mean above value. This is the block model variable to store the mean above the cutoff computed from the distribution assembled from realisations. If a variable is not supplied, then this calculation will be ignored. Provide a default value in case no realisations fall within the minimum/maximum trimming limits.
-
Specify the Mean below value. This is block model variable to store the mean below the cutoff computed from the distribution assembled from realisations. If a variable is not supplied, then this calculation will be ignored. Provide a default value in case no realisations fall within the minimum/maximum trimming limits.
-
-
The Grade at a given probability section is used to read the distribution from the probability axis. At a given probability a grade will be obtained.
-
Enter the Cdf probability (between 0 an 1) to read the grade that correspond to it. For example, if 0.5 is given then the median grade is returned.
-
Specify the P quantile variable where the grade corresponding to the given probability will be stored. Provide a default value in case no realisations fall within the minimum/maximum trimming limits.
-
-
Use the Symmetric interval limits section to find the grades that define a given symmetrical probability interval.
Enter the Interval width of the probability (between 0 to 1). For example a probability interval of 0.5, will be limited by the first and third quartiles.
-
Specify the block model variable where the grade that defines the Lower limit for the given symmetrical interval will be stored. If a variable is not supplied, then this calculation will be ignored. Provide a default value in case no realisations fall within the minimum/maximum trimming limits.
-
Select the block model variable where the grade that defines the Upper limit for the given symmetrical interval will be stored. If a variable is not supplied, then this calculation will be ignored. Provide a default value in case no realisations fall within the minimum/maximum trimming limits.
-
-
Select the block model where the conditional Variance, obtained from the distribution assembled from the realisations, will be stored. If a variable is not supplied, then this calculation will be ignored. Provide a default value in case no realisations fall within the minimum/maximum trimming limits.
-
Define the minimum and maximum Trimming limits. These are the acceptable values for the simulation variable. Realisations that do not fall between this limit, will be discarded. If you are using Gaussian units, then negative values should be allowed. If you are using non-negative grades, then negative values should be discarded.
Click Apply and Run to begin the simulation. This will save your settings in to the specification file and start the simulation run.
Click OK to save your settings to the specification file without running the simulation.
Click Cancel to close the panel without saving any settings.

